개요
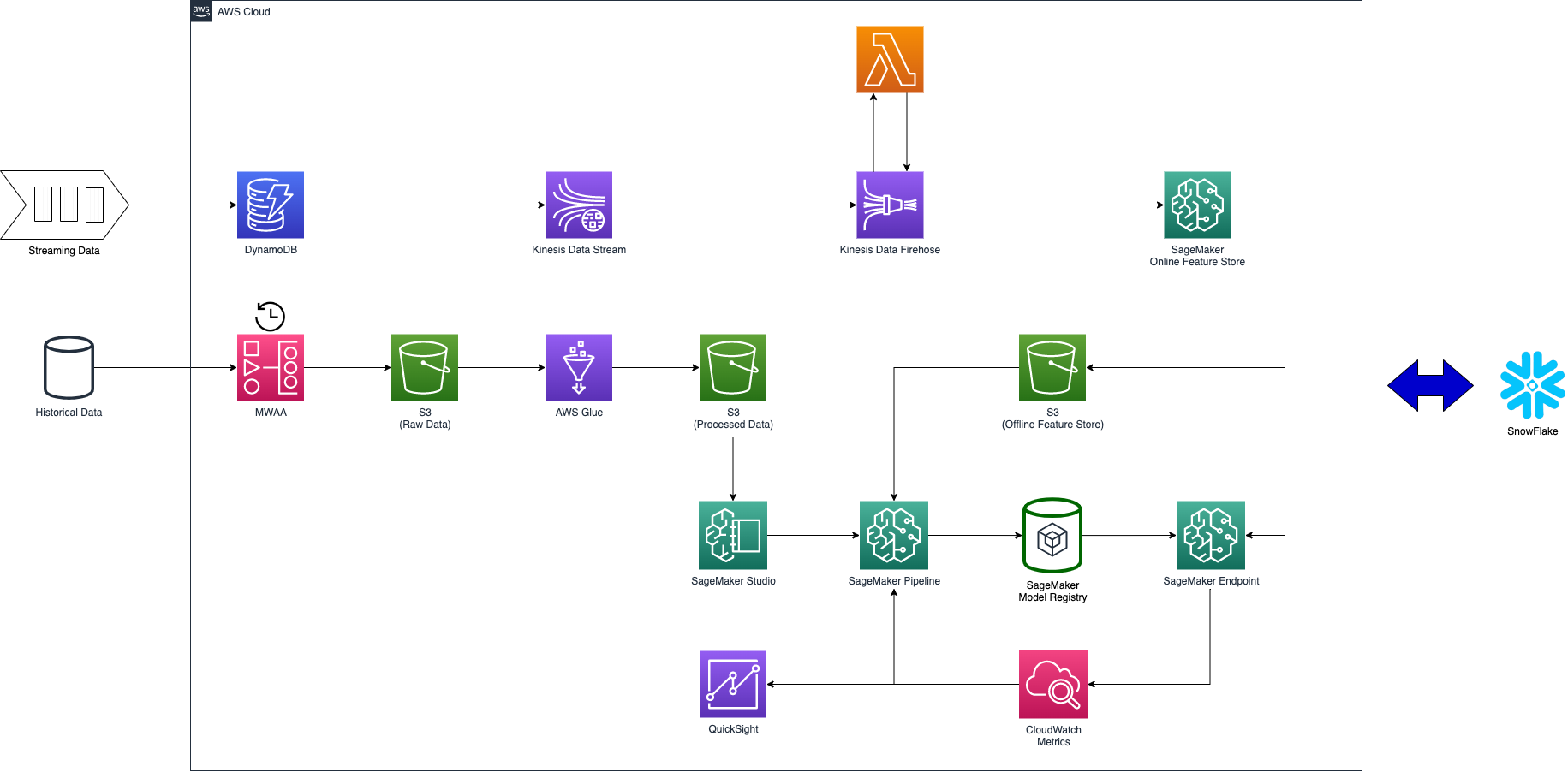
- AWS Data/MLOps 인프라 이키텍처 샘플
AWS와 Snowflake로 Data/MLOps 인프라 아키텍처링을 해보았습니다. 데이터 분석 솔루션만 Snowflake를 사용하고 나머지는 모두 AWS에서 제공하는 서비스입니다. Data와 MLOps 인프라를 통합하여 모두 표현하다 보니 조금 복잡해 보이므로 항목 별로 하나씩 살펴보겠습니다.
데이터 분석 인프라

데이터 분석 인프라는 Snowflake 기반의 Lakehouse 구조입니다. 순수 AWS 서비스로만 데이터 인프라를 구성하시려면 Snowflake 대신 AWS Athena를 사용하시면 됩니다.
AWS에서 데이터 인프라를 구축할 때는 S3 버킷의 최대 크기는 5TB, 계정당 최대 버킷 1,000개까지 사용할 수 있는 걸 감안해서 사용하시기 바랍니다.
1. 추출 & 적재
Amazon MWAA로 일정 주기로 Historical Data를 S3에 적재합니다. 위 그림에는 Historical Data가 하나의 저장소에서 가져오는 것처럼 표현되어 있지만, 실제로는 여러 소스에서 데이터를 추출하여 적재합니다. 기본적으로 필요한 Raw Data는 모두 적재하지만, 클라우드 비용을 고려하여 데이터 분석 및 모델 개발에 활용될 여지가 없는 데이터까지 무분별하게 모두 쌓지는 않습니다. 어떤 데이터가 어떤 식으로 활용될지는 엔지니어가 판단할 영역이 아니므로, 데이터 과학자(분석가)분들과 협의하여 진행하시기 바랍니다.
2. 데이터 분석
Snowflake를 활용하여 Raw Data 분석을 수행합니다. Snowflake 계정 생성 시 AWS 클라우드 서비스와 S3 버킷과 같은 리즌 (Ex> ap-northeast-2)을 사용하도록 설정하여 데이터 전송 비용을 줄일 수 있습니다. (Snowflake의 데이터 전송 비용은 Understanding Snowflake Pricing 문서의 DATA TRANSFER 항목을 참고하세요.)
이 단계에서 BI나 머신러닝 모델에 사용할 정제된 데이터를 추려 냅니다. (위 그림에서 Processed Data)
3. 데이터 변환
데이터 엔지니어링에 가장 많은 비중을 차지하고 있는 데이터 변환 과정입니다. 2번 과정에서 정제된 데이터의 스키마가 정해지면 AWS Glue로 지속적 변환이 되도록 설정합니다. Glue 이 외에도 데이터 변환 수단은 무궁무진하니 요구 처리량, 비용, 편의성 등을 고려하여 데이터 변환 도구를 선택해야 합니다. (Lambda, Data Pipeline, EMR, Redshift, Batch, Snowflake, EKS, …)
4. BI (Business Intelligence)
변환된 데이터에서 데이터 중심 의사결정을 할 수 있도록 QuickSight로 다양한 시각적 대시보드를 생성합니다.
실시간 데이터 처리 인프라

실시간 데이터 처리 인프라는 머신러닝 모델의 온라인 피처(=모델 추론의 입력 데이터)를 생성하는 것에 초점을 두고 표현하였습니다. 변환된 스트리밍 데이터를 전달하는 대상(4번)만 변경하면 다른 곳에도 활용할 수 있습니다.
1. 스트리밍 데이터 적재
스트리밍 데이터를 DynamoDB에 그대로 저장합니다. 스트리밍 데이터 재현이 필요하지 않거나, Historical Data에 스트리밍 데이터가 모두 포함되어 있으면 비용 절감을 위해 이 과정을 생략할 수도 있습니다.
2. 스트리밍 데이터 추출
Kinesis Data Stream으로 스트리밍 데이터를 추출합니다. DynamoDB에 저장되는 스트리밍 데이터를 추출하려면 Kinesis Data Streams를 사용하여 DynamoDB 변경 사항 캡처 문서를 참고하세요.
3. 스트리밍 데이터 변환
Kinesis Data Firehose를 사용하여 실시간 스트리밍 데이터를 머신러닝 모델에 사용할 온라인 피처로 변환합니다.
4. 온라인 피처 스토어
온라인 피처로 변환된 스트리밍 데이터를 SageMaker 피처 스토어에 로드 합니다.
MLOps 인프라

MLOps 인프라는 대부분 AWS SageMaker를 활용하여 아키텍처링 하였습니다. SageMaker의 서브 서비스인 Studio, Pipeline, Model Registry, Endpoint, Feature Store 를 ML 프로세스별로 표현하였습니다. Cloud Watch에서 서비스 중인 모델 성능을 모니터링하며, 데이터 드리프트를 감지하게 되면 ML 파이프라인을 트리거하여 지속적 학습을 수행합니다.
1. ML 실험
SageMaker Studio 환경에서 정제된 데이터를 활용하여 ML 파이프라인을 개발하기 위한 실험을 합니다. 여기서 사용하는 정제된 데이터 (Processed Data)는 데이터 탐색의 결과물입니다. (데이터 분석 인프라의 데이터 변환)
2. ML 파이프라인
ML 파이프라인은 머신러닝 모델 종류와 머신러닝으로 해결하려는 비즈니스 문제마다 다르지만, 일반적으로 데이터 로드 -> 데이터 검증 -> 데이터 준비 -> 모델 학습 -> 모델 평가 -> 모델 검증 단계로 이루어집니다. 위 그림에는 SageMaker Pipeline 하나만 표현되어 있지만, 여기에는 ML 파이프라인의 각 단계가 포함됩니다.
3. 모델 레지스트리
ML 파이프라인 실행이 완료되면 학습된 모델은 모델 레지스트리에 등록됩니다.
4. 모델 서빙
모델 레지스트리에 등록된 모델을 SageMaker Endpoint로 배포합니다.
5. 모델 추론
온라인 피처 스토어에서 추론할 데이터를 적재하여 Endpoint에서 추론을 실행합니다. 사용된 온라인 피처는 오프라인 피처 스토어에 저장하여 모델 평가 및 재학습에 사용합니다. ML 모델 추론 서비스가 필요한 서비스 인프라에서 Endpoint로 추론 요청을 하여 추론 결과를 사용합니다. (동기식, 비동기식)
6. 모니터링과 지속적 학습
Endpoint로 서비스 중인 모델의 성능을 모니터링 합니다. Cloud Watch Metrics에서 데이터 드리프트 발생 임계점이 감지되면, ML 파이프라인을 트리거하여 새로운 데이터로 모델을 재학습합니다. (지속적 학습)
결론
데이터는 머신러닝을 구성하는 하나의 큰 축이기 때문에, 데이터와 머신러닝은 서로 떼려야 뗄 수 없는 관계입니다. 작년부터 데이터 중심 AI 가 대두하면서 머신러닝 프로젝트에 데이터의 중요성은 점점 더 강조되고 있습니다. 그럼에도, 데이터와 머신러닝은 관련 직무와 팀이 분리되어 있다 보니, 데이터와 머신러닝 인프라도 제각각인 곳이 많습니다.
이 글에서 데이터와 MLOps 인프라를 통합한 인프라를 AWS 클라우드 서비스를 예시로 아키텍처링 해보았습니다. 데이터 팀은 ML 인프라를, ML 팀은 데이터 인프라를 참고하여 데이터가 어떻게 처리되고, 모델이 어떻게 생성되는지 인프라 측면에서 이해하는 데 도움이 되셨으면 좋겠습니다.