개요
어느 회사의 ML 팀은 회사의 비지니스 문제를 해결하기 위해 딥러닝 알고리즘이 가장 적합하다고 결론을 내렸습니다. 데이터 엔지니어는 데이터 과학자와 논의하여 필요한 데이터 수집하고 데이터 과학자의 데이터셋 준비를 지원합니다. 데이터 과학자는 수집된 데이터를 탐색하고 데이터 엔지니어와 협업하여 필요한 데이터셋을 준비합니다. 딥러닝을 사용하기로 하였으므로 데이터 탐색이나 피처 엔지니어링이 많이 필요하지 않습니다. 모델 학습이 완료되고 오프라인 데이터셋에서 모델 성능을 검증해보니, 비지니스 문제 해결에 충분한 하다는 것을 확인하였습니다.
자, 이제 저와 같은 머신러닝 엔지니어의 턴 입니다. 개발된 딥러닝 모델을 배포해야하는 시기가 온 것 입니다. MLOps 개념이 널리 알려지기 전의 ML 종사자들은 이 단계가 ML 프로젝트의 종착점으로 착각 했었지만, 이제 우리는 그렇지 않다는 것을 잘 알고 있습니다. 모델 제품화의 첫 걸음을 이제 막 딛은 것이지요.
딥러닝 모델 배포의 첫 단계는 모델 체크포인트 파일을 서빙용 모델로 변환하는 것 입니다. 학습된 딥러닝 체크포인트 파일을 변환하여, 서빙(추론)에 최적화되어 있는 다양한 딥러닝 모델 서빙용 포맷들이 있으며, 모델을 배포하는 타겟에 따라 적합한 포맷이 다릅니다.
배포 타겟별 서빙용 모델 유형
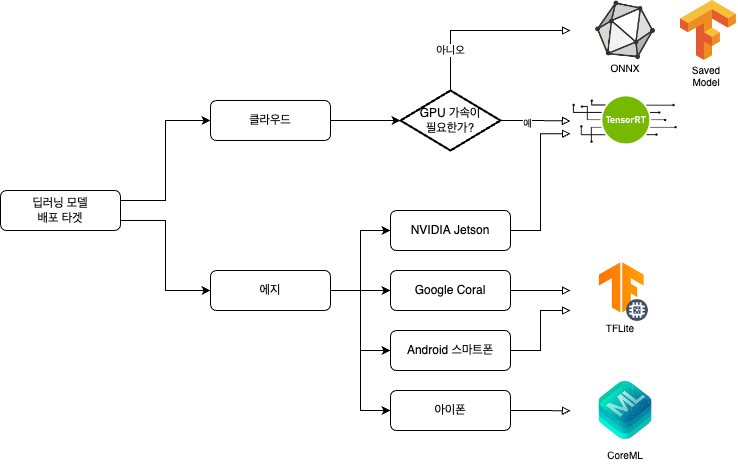
- 배포 타겟별 서빙용 모델 유형 — ONNX, Saved Model, TensorRT, TFLite, CoreML
모델을 어디에 배포하느냐에 따라 변환해야하는 서빙용 모델의 유형이 달라집니다. 위 그림은 배포 타겟 별로 PyTorch 모델을 변환해야 하는 포맷을 정리한 그림 입니다. 여러 포맷들 중에서 많이 사용되는 5개 포맷만 정리하였습니다. 왜 위와 같이 모델을 변환해야 할까요? 모델 포맷마다 모델 성능의 차이는 거의 없고, 추론 속도는 확연히 차이가 나기 때문 입니다. (아래 표 참고)
| Colab Pro+ CPU | MacOS Intel CPU | Colab Pro+ GPU (V100) | ||||
| 모델 유형 | mAP@0.5:0.95 | 추론 시간 (ms) | mAP@0.5:0.95 | 추론 시간 (ms) | mAP@0.5:0.95 | 추론 시간 (ms) |
| PyTorch | 0.4623 | 127.61 | 0.4623 | 222.37 | 0.4623 | 10.19 |
| TorchScript | 0.4623 | 127.61 | 0.4623 | 231.01 | 0.4623 | 6.85 |
| ONNX | 0.4623 | 69.34 | 0.4623 | 54.41 | 0.4623 | 14.63 |
| OpenVINO | 0.4623 | 66.52 | 0.4623 | 40.74 | NaN | NaN |
| TensorRT | NaN | NaN | NaN | NaN | 0.4617 | 1.89 |
| CoreML | NaN | NaN | 0.4620 | 39.09 | NaN | NaN |
| TensorFlow SavedModel | 0.4623 | 123.79 | 0.4623 | 153.32 | 0.4623 | 21.28 |
클라우드 서빙용 모델 변환
YOLOv5 모델 변환 예제:
클라우드에 배포된 모델은 일괄 처리와 실시간 처리 두 가지 유형에 사용됩니다. 일괄 처리는 주기적으로 실행되는 데이터 파이프라인 (혹은 머신러닝 파이프라인)에서 모델을 로드하여, 한번에 많은 입력 데이터를 추론 합니다. 실시간 처리에 사용되는 모델은 모델을 마치 마이크로서비스처럼 배포하여 스트림 데이터를 입력받아 추론 결과 스트림 생성하거나, 다른 마이크로서비스에서 요청을 받은 데이터를 추론하여 결과를 응답 합니다.
실시간 처리에 비해 일괄 처리에 사용되는 모델은 추론 시간에 덜 민감하지만, 클라우드에서 처리 시간은 곧 비용과 직결되므로 일괄 처리도 추론이 빠르면 빠를수록 좋습니다. 클라우드 환경에 딥러닝 모델을 배포시에는 다음과 같은 모델 유형을 많이 사용 합니다:
- ONNX: 근래 가장 인기있는 딥러닝 모델 서빙 포맷입니다. 평균적으로 대부분의 배포 환경에서 추론 속도가 준수하며, 다른 포맷으로 변환이 용이합니다.
- Saved Model: Tensorflow로 학습된 모델을 클라우드에 배포할때 사용 합니다.
- TensorRT: 모델 추론의 H/W 가속기로 NVIDIA GPU를 사용할때 가장 빠릅니다.
ONNX
ONNX (Open Neural Network Exchange)는 서로 다른 프레임워크 환경 (Tensorflow, PyTorch)에서 만들어진 모델들을 서로 호환되게 사용할 수 있도록 만들어진 공개 플랫폼입니다. Tensorflow에 비해 PyTorch가 부족한 배포 최적화 부분을 ONNX가 매워주고 있습니다. 모델 파일 확장자는 .onnx를 사용하며, 다양한 실행 프로바이더를 지원하는 ONNX Runtime을 런타임 환경으로 사용합니다.
PyTorch 모델을 ONNX로 변환하려면 torch.onnx.export() 함수를 사용하시면 됩니다.
- PyTorch 모델 (
yolov5s.pt) -> ONNX 모델 (yolov5s.onnx) 예제
import onnx
import torch
import onnxsim
output_model = 'yolov5s.onnx'
sample_input = torch.zeros(1,3,320,640) # batch, channel, height, width
torch.onnx.export(
model.cpu(),
sample_input.to("cpu"),
output_model,
verbose=False,
opset_version=12,
do_constant_folding=True,
input_names=['images'],
output_names=["output0"],
dynamic_axes=None)
model_onnx = onnx.load(output_model) # load onnx model
onnx.checker.check_model(model_onnx) # check onnx model
# Metadata
d = {'stride': model.stride, 'names': model.names}
for k, v in d.items():
meta = model_onnx.metadata_props.add()
meta.key, meta.value = k, str(v)
# Simplify
model_onnx, check = onnxsim.simplify(model_onnx)
onnx.save(model_onnx, output_model) # Save the ONNX model
Saved Model
- Tensorflow Saved Model 저장과 로드
import tensorflow as tf
(...)
model = SomeModel()
tf.saved_model.save(model, "/tmp/some_model/1/") # 모델 저장
(...)
model = tf.saved_model.load("/tmp/some_model/1/") # 모델 로드
Saved Model은 Tensorflow의 서빙 포맷 입니다. ONNX로 인해 지금은 무색해졌지만, Tensorflow가 PyTorch에 비해 배포에 좋은 이유 중의 하나가 Saved Model과 TFLite 등의 별도의 서빙 포맷을 가지고 있다는 점 이었습니다. 아래 밈과 같이 꼰대용 프레임웍이라고 놀림을 받고 있지만, 2022년 현재에도 배포에 한정하면 Tensorflow는 여전히 최고의 프레임웍 입니다.

- Tensorflow는 꼰대들의 전유물?
라떼는 말이야…(출처> Josh Tobin 트윗)
더 읽을거리: PyTorch vs TensorFlow in 2022
TensorRT
NVIDIA GPU에서 추론 속도가 가장 빠른 포맷 입니다. A100, V100과 같은 고사양 GPU 뿐만 아니라 Jetson과 같은 에지용 GPU에도 가장 빠르게 동작합니다. 즉, 딥러닝 모델 추론 가속기로 NVIDIA GPU를 사용하시면 TensorRT 포맷이 최고의 서빙 포맷 입니다.
- ONNX 모델을 TensorRT로 변환하기 (
yolov5s모델)
import tensorrt as trt
input_model = "yolov5s.onnx"
output_model = "yolov5s.trt"
logger = trt.Logger(trt.Logger.INFO)
builder = trt.Builder(logger)
config = builder.create_builder_config()
workspace = 4 # workspace size (GB)
config.max_workspace_size = workspace * 1 << 30
flag = (1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
network = builder.create_network(flag)
parser = trt.OnnxParser(network, logger)
if not parser.parse_from_file(input_model):
raise RuntimeError(f'failed to load ONNX file: {input_model}')
inputs = [network.get_input(i) for i in range(network.num_inputs)]
outputs = [network.get_output(i) for i in range(network.num_outputs)]
if builder.platform_has_fast_fp16:
config.set_flag(trt.BuilderFlag.FP16)
with builder.build_engine(network, config) as engine, open(output_model, 'wb') as t:
t.write(engine.serialize())
Edge 서빙용 모델 변환
배포 타겟이 스마트폰과 같은 edge device라면, 해당 장치에 따라 서빙 포맷이 달라집니다. 예를들면, 안드로이드 스마트폰에서 추론 연산을 하는 안드로이드 앱에 들어가는 모델이라면 TFLite 포맷이 가장 적합합니다. 아이폰, 맥북등과 같은 애플 장치에서 추론 연산을 하는 모델이라면 CoreML 모델이 가장 좋습니다. Edge 서빙은 클라우드 서빙에 비해 다음과 같은 장점을 가지고 있습니다:
- 짧은 응답속도: 모델 추론시, 클라우드 서버에 접근이 없이 장치에서 수행하므로 응답속도가 빠름.
- 개인 정보 보호: 클라우드 서버에 개인 정보를 전달하지 않아서 개인 정보 노출 위험이 없음.
- 네트워크 불필요: 클라우드 서버에 접근이 불필요하기 때문에 네트워크 망에 연결될 필요 없음.
- 저전력: 네트워크 통신을 위한 전력 소모가 없으며, 작은 사이즈의 모델 구동으로 컴퓨팅 전력 소모가 적음
Edge용 모델 변환시 신경써야하는 점이 딥러닝 모델 추론 H/W 가속기 (NPU, DSP, …)에서 추론 연산이 최적화 되도록 데이터 포맷을 변환해야 하는대요. 이것을 양자화 (Quantization)라고 합니다. 아래는 몇가지 기본적인 양자화 포맷 가이드라인 입니다:
From 원본 체크포인트 파일의 데이터 포맷: float 32bit ->
- To NVIDIA GPUs: ->
float 16bit - To Google TPU, AWS Inferentia: ->
bfloat16 - To 연식이 조금된 스마트폰: ->
int8 - To 기타 딥러닝 추론 H/W 가속기가 탑재된 장치들: -> 칩 스팩 문서 확인 또는 타입별 양자화후 테스트
Edge 장치에 딥러닝 모델을 배포시에는 다음과 같은 모델 유형을 많이 사용 합니다:
- CoreML: 애플에서 만든 장치들
- TFLite: 구글 안드로이드 장치들
- TensorRT: NVIDIA Jetson 장치들
- ONNX: ONNX Runtime이 동작하고, 적합한 프로바이더가 있는 장치들
TFLite
TensorFlow Lite는 TensorFlow 모델을 스마트폰이나 임베디드, IoT 기기에서 구동하기 위한 ML 툴 입니다. Tensorflow 모델이 동작하는 환경이 안드로이드 장치라면 TFLite 포맷으로 변환하여 서빙하는 것이 가장 좋습니다. 기반이 되는 모델이 Tensorflow 모델이므로, Tensorflow의 Keras 포맷이나 Saved Model 포맷에서 TFLite 포맷으로 변환 합니다.
- Tensorflow Saved Model ->
.tflite변환
import tensorflow as tf
saved_model = "./saved_model"
output_model = "yolov5s.tflite"
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model)
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS]
converter.target_spec.supported_types = [tf.float16]
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_model = converter.convert()
open(output_model, "wb").write(tflite_model)
TMI: 구글에서 사용하는 직렬화된 파일 포맷은 Proto buffer가 많습니다만,
.tflite파일은 Flat buffer로 직렬화 되어 있습니다.
CoreML
CoreML은 Apple에서 사용하는 딥러닝 포맷 입니다. TensorRT 포맷이 NVIDIA GPU에서 추론 속도가 가장 빠른 것처럼, CoreML은 애플 장치들 (아이폰, 아이패드, 맥북)에서 비교적 최고의 성능(속도)를 냅니다. (장치 개발사에서 직접 만든 포맷이 최적화가 가장 잘되어 있을수밖에….)
- Torch Script -> CoreML 모델 변환
import coremltools as ct
import torch
output_model = "yolov5s.mlmodel"
sample_input = torch.zeros(1,3,320,640) # batch, channel, height, width
ct_model = ct.convert(torch_script_model, inputs=[ct.ImageType('image', shape=sample_input.shape, scale=1 / 255, bias=[0, 0, 0])])
bits, mode = (16, 'linear') # Quantization option
ct_model = ct.models.neural_network.quantization_utils.quantize_weights(ct_model, bits, mode)
ct_model.save(output_model)
결론
딥러닝 모델 서빙용 포맷 변환은 머신러닝 엔지니어링의 한 부분으로 모델러 (ML 모델을 만드는 사람 — 데이터 과학자, 연구원)가 아닌 저와 같은 엔지니어가 모델러와 협업하여 주로 수행합니다. MLOps가 대중화 되기 이전 수동 프로세스로 ML 프로젝트를 수행하던 시절에는 모델 개발 은 학습용 체크포인트 파일을 만드는 것까지를 의미할 때가 많았습니다. 이 시절에는 모델 최적화 단계를 따로 두고 머신러닝 엔지니어(혹은 그와 같은 역활을 하는 사람)이 모델 최적화하는 과정을 거쳐 모델을 배포하곤 하였습니다.
현재 고도화된 ML 팀에는 MLOps를 적용하여 ML 프로세스의 많은 부분을 자동화하고 있고, 모델이 아닌 ML 파이프라인 단위로 개발을 하고 있습니다. 즉, MLOps 관점에는 딥러닝 모델을 서빙용으로 변환하는 것은 모델 개발 (또는 ML 파이프라인 개발) 과정에 포함하여 진행하는편이 수월합니다. ML 파이프라인의 모델 변환 단계가 될 수 있겠네요.
딥러닝 모델 추론 최적화는 이 글에서 다루었던 모델 포맷 변환 외에도 다양한 기법들이 존재합니다. 모델 네트워크를 구축할때는 프로파일러로 레이어별로 실행 속도를 확인하여 네트워크를 수정하면서 추론 속도를 최적화를 할 수 있습니다. 그 외에도, knowledge distillation, weight clustering, pruning, quantization aware training 등의 모델 성능 감소가 거의 없으면서 추론 속도를 높이는 많은 기법들이 존재 합니다.
ML 파이프라인에 모델 변환 단계를 통합하실때는 작은 데이터셋으로 Sanity check를 꼭 포함하시기 바랍니다. (변환된 모델의 추론 결과 정합성 확인, 추론 속도 확인) 가끔 생각지도 못한 버그를 사전에 걸러내어 엔지니어의 야근을 방지해줍니다. :-)