개요
실험실을 벗어나 상용 딥러닝 모델 개발 경험이 있는 분이라면 데이터셋을 준비하는 것이 매우 힘들다는 것에 공감하실 겁니다. 더구나 데이터셋 관리가 되지 않아 재현성을 포기한채 모델 개발하는 곳도 보았습니다. 이런 ‘해석 불가능한’ 모델은 거버넌스로 인해 힘들게 개발을 완료 하더라도 법적인 제약으로 상용화가 불가능 할 수도 있습니다.
이 기사에는 비전 데이터를 예시로 수집된 데이터에서 데이터셋 생성까지 과정을 자동화하는 샘플 아키텍처 제시하고, 비디오 데이터에서 이미지 데이터를 샘플링하는 간단한 파이프라인 예제를 작성하였습니다.
비전 데이터셋은 데이터셋에 추가 할 이미지 샘플링을 어떻게 하느냐에 따라 딥러닝 프로세스 전체에 막대한 영향을 끼칩니다. 가장 좋은 방법은 SME (Subject Matter Expert)가 직접 데이터셋에 필요한 이미지 파일을 캡처해서 수집하는 것이지만, 이런 방식은 프로젝트에 따라 매우 힘들거나 너무 비효율적 일 수가 있습니다. 이 글에서 제시하는 아키텍처는 비디오 데이터를 수집 데이터로 하고, 데이터 라벨링이 필요한 이미지 데이터를 추출해서 데이터셋을 생성하는 것으로 가정 하였습니다.
AI 선도 업체들은 이미 반지도 학습 (Semi-supervised Learning), 능동적 학습 (Active Learning), 자동 라벨링 (Auto Labeling) 등의 현대적인 기법들을 적용하여 라벨링에 소요되는 비용을 최소화하고, 효율적으로 데이터셋 생성을 하고 있습니다. 이 글은 최신 라벨링 기법들 적용에 앞서 데이터셋 아키텍처를 어떻게 해야 할지 갈피를 잡지 못하는 분들을 위해 작성하였습니다.
Taehun/vision-dataset-sample-infra Github 저장소에서 이 기사에서 다루는 예제 코드를 확인 하실 수 있습니다.
비전 데이터셋 아키텍처 on GCP
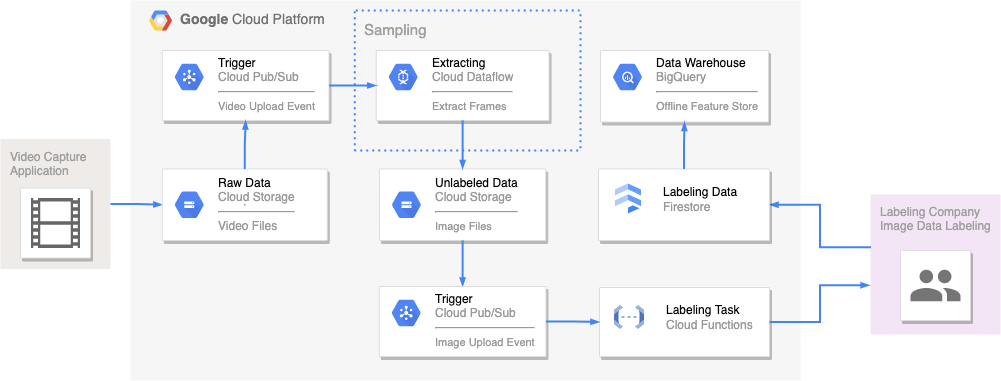
Raw Data
솔루션: Cloud Storage
녹화된 비디오 파일을 GCS에 업로드 합니다. 수집 단말에 녹화가 끝난후 비디오 파일이 생성되면 아래와 같은 코드로 자동 업로드 되도록 구현할 수 있습니다. (수집 단말에 인터넷 접속 및 GCP 서비스 계정 필요) 이 항목에서는 프로젝트에 따라 비디오 파일명 (경로 포함)을 어떻게 할지 표준을 정하는 것이 중요합니다. video_id와 같은 유니크한 키 값이 있다면 video_id.mp4처럼 파일명을 지정할 수 있습니다.
- GCS에 비디오 파일 업로드 Python 예제
from google.cloud import storage
import os
# video_file_name = "<SOME_VIDEO_FILE>.mp4"
raw_data_bucket = os.environ["RAW_DATA_BUCKET"]
collector_id = os.environ["COLLECTOR_ID"]
storage_client = storage.Client()
bucket = storage_client.bucket(raw_data_bucket)
blob = bucket.blob(f"{collector_id}/{video_file_name}")
blob.upload_from_filename(video_file_name)
Trigger
솔루션: Pub/Sub
GCS 버킷에 비디오 파일 및 이미지 파일 업로드 이벤트를 가져오기 위해 Pub/Sub 토픽을 생성합니다. 버킷에 notification.create() 함수로 알림을 구성 할 수 있습니다. 사용하는 GCS 이벤트 유형은 OBJECT_FINALIZE 입니다.
- 버킷 생성 및 이벤트 알림 생성 예제
from google.cloud import storage
def create_bucket_notifications(bucket_name, topic_name):
"""Creates a notification configuration for a bucket."""
# The ID of your GCS bucket
# bucket_name = "your-bucket-name"
# The name of a topic
# topic_name = "your-topic-name"
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
notification = bucket.notification(topic_name=topic_name)
notification.create()
print(f"Successfully created notification with ID {notification.notification_id} for bucket {bucket_name}")
좀 더 자세한 내용은 Cloud Storage용 Cloud Pub/Sub 알림, Cloud Storage용 Pub/Sub 알림 구성, Notification Polling 예제를 참고하세요. Github 예제 코드에는 Terraform으로 인프라를 생성할 때 Pub/Sub 토픽을 생성하도록 구현하였습니다.
resource "google_storage_notification" "notification" {
bucket = google_storage_bucket.dataset.name
payload_format = "JSON_API_V1"
topic = google_pubsub_topic.topic.id
event_types = ["OBJECT_FINALIZE"]
depends_on = [google_pubsub_topic_iam_binding.binding]
}
Extracting
솔루션: Dataflow
이 아키텍처에서 핵심이 되는 부분 입니다. 수집한 비디오 파일에서 데이터셋으로 사용할 이미지를 샘플링하는 ETL에 해당 됩니다. 능동적 학습 알고리즘을 여기에 추가 하시면 됩니다. 먼저, 가장 단순하게 1초마다 1 프레임을 추출하는 예제로 ETL을 만들어 보겠습니다.
가장 먼저 비디오 파일에서 프레임을 추출하려면 파이썬 기준 cv2 패키지가 필요합니다. Dataflow 워커에서 cv2 패키지 사용하기 위해 여러 방법이 있지만, 저는 커스텀 컨테이너를 사용하였습니다.
- Dockerfile 샘플
FROM apache/beam_python3.8_sdk:2.40.0
RUN apt-get update && apt-get install -y --no-install-recommends \
ffmpeg=7:4.3.4-0+deb11u1 \
libsm6=2:1.2.3-1 \
libxext6=2:1.3.3-1.1 \
&& apt-get clean && rm -rf /var/lib/apt/lists/*
RUN pip install -U pip && pip install --no-cache-dir \
opencv-python==4.6.0.66 \
google-cloud-storage==2.4.0 \
google-cloud-pubsub==2.13.4
데이터 파이프라인의 첫 단계는 Pub/Sub 토픽에서 메세지를 가져오는 것 입니다. Apache Beam의 io.ReadFromPubSub()로 Pub/Sub 메세지를 가져올 수 있습니다.
다음으로 Pub/Sub 메세지에서 비디오 파일 GCS 버킷의 파일 업로드 이벤트가 발생했으면 비디오 파일 목록을 다음 단계로 전달 합니다. 다음 단계에서 비디오 파일 다운로드를 위해 Signed URL을 생성하여 전달 하였습니다. (만료시간 5분) 이 단계에는 GCP 서비스 계정 인증이 필요하여, GCS에 서비스 계정 키 파일을 업로드하여 사용 할수 있도록 파이프라인을 구현 하였습니다. (--key_file 옵션)
class GetVideoFiles(beam.DoFn):
(...)
def _get_video_signed_url(self, bucket_name, blob_path, creds):
import datetime
from google.cloud import storage
from google.oauth2 import service_account
credentials_json = json.loads("\n".join(creds))
credentials = service_account.Credentials.from_service_account_info(credentials_json)
client = storage.Client(credentials=credentials)
bucket = client.bucket(bucket_name)
blob = bucket.blob(blob_path)
return blob.generate_signed_url(datetime.timedelta(seconds=300), method="GET")
def process(self, message, creds):
"""Get uploaded vidoe files in Google Cloud Storage."""
import json
import os.path as osp
from pathlib import Path
msg_obj = json.loads(message)
video_path = "gs://" + str(Path(osp.join(msg_obj["bucket"], msg_obj["name"])))
video_folder = str(Path(osp.join(msg_obj["bucket"], msg_obj["name"])).parent)
logging.debug(f"Input Path = {self.input_path}, video_foldet = {video_folder}")
prefix_len = len("gs://")
if self.input_path[prefix_len:] == video_folder:
video_file_url = self._get_video_signed_url(msg_obj["bucket"], msg_obj["name"], creds)
logging.info(f"GetVideoFiles: Video file = {video_path}")
logging.info(f"GetVideoFiles: Signed Video URL {video_file_url}")
yield (video_path, video_file_url)
마지막으로 전달 받은 비디오 파일의 프레임을 추출하여 이미지 파일 버킷에 저장합니다. 여기서는 cv2 패키지를 사용하여 비디오 파일의 Frame rate 설정에 따라 1초마다 1 프레임씩 이미지 파일을 추출합니다.
class ExtractFrames(beam.DoFn):
(...)
def process(self, element):
(...)
cap = cv2.VideoCapture(f"/tmp/{videoID}.mp4")
frameRate = cap.get(5) # Get frame rate
while cap.isOpened():
frameId = cap.get(1) # Current frame number
ret, frame = cap.read()
if ret != True:
logging.warning("ExtractFrames: Failed to read frame!")
break
# Sample the frames each 1 second
if frameId % math.floor(frameRate) == 0:
filename = f"{imagesFolder}/{str(int(frameId))}.jpg"
is_success, buffer = cv2.imencode(".jpg", frame)
if is_success != True:
logging.warning("ExtractFrames: Failed to encoding frame!")
continue
# Write JPG file to GCS
with beam.io.gcsio.GcsIO().open(filename=filename, mode="wb") as f:
f.write(buffer)
logging.info(f"UploadFrames: {filename}")
cap.release()
파이프라인 설정은 다음과 같이 작성하였습니다. GetVideoFiles 단계에서 서비스 계정 인증이 필요하여, GCS에서 서비스 계정 키 파일을 읽어오는 단계가 추가되어 있습니다. (credentials)
def run(input_topic, vidoe_path, image_path, key_file, pipeline_args=None):
# Set `save_main_session` to True so DoFns can access globally imported modules.
pipeline_options = PipelineOptions(pipeline_args, streaming=True, save_main_session=True)
with beam.Pipeline(options=pipeline_options) as pipeline:
credentials = pipeline | "Read Credentials from GCS" >> ReadFromText(key_file)
(
pipeline
| "Read from Pub/Sub" >> beam.io.ReadFromPubSub(topic=input_topic)
| "Get the video files" >> beam.ParDo(GetVideoFiles(vidoe_path), pvalue.AsList(credentials))
| "Extract video frames" >> beam.ParDo(ExtractFrames(image_path))
)
Labeling Task
솔루션: Cloud Functions
Unlabeled Data 버킷에 이미지 파일이 업로드되면 Pub/Sub은 Labeling Task 함수를 트리거 합니다. 이 함수는 라벨링 업체에 업로드된 이미지 파일의 라벨링 요청을 보내는 역활을 수행 합니다. 이 항목은 라벨링 업체마다 모두 상이하므로 계약한 업체의 API에 맞게 작성하시기 바랍니다.
- Scale AI의 작업 요청 API 예제
def request_labeling(event, context):
"""Triggered from a message on a Cloud Pub/Sub topic.
Args:
event (dict): Event payload.
context (google.cloud.functions.Context): Metadata for the event.
"""
import base64
import requests
from scaleapi.tasks import TaskType
from scaleapi.exceptions import ScaleDuplicateResource
pubsub_message = base64.b64decode(event['data']).decode('utf-8')
event_obj = json.loads(pubsub_message)
bucket = os.environ["BUCKET"]
image_path = os.environ["IMAGE_PATH"]
print(bucket, image_path)
# Check the image file upload event
if bucket == event_obj["bucket"] and image_path == str(Path(event_obj["name"]).parent):
print(f"{event_obj['name']} file is uploaded!")
payload = dict(
project = "PROJECT_NAME",
callback_url = "http://www.example.com/callback",
instruction = "Draw a box around each cars.",
attachment_type = "image",
attachment = f"gs://{bucket}/{image_path}",
unique_id = "c235d023af73",
geometries = {
"box": {
"objects_to_annotate": ["pedestrian", "rider", "car", "truck", "bus", "motorcycle", "bicycle"]
"min_height": 10,
"min_width": 10,
}
},
)
try:
# Create labeling task
client.create_task(TaskType.ImageAnnotation, **payload)
except ScaleDuplicateResource as err:
print(err.message) # If unique_id is already used for a different task
Labeling Data
솔루션: Cloud Firestore
라벨링 작업이 끝나면 업체에서 어노테이션 데이터를 전달해 줍니다. 업체에서 제공하는 API가 모두 다르므로 어노테이션 데이터를 받는 과정도 모두 상이합니다. 여기서는 가장 범용으로 사용할 수 있는 NoSQL 저장소인 Firestore로 어노케이션 데이터를 수신하도록 구성하였습니다. (라벨링 업체측에 Cloud Firestore에 접근이 가능한 서비스 계정이 있어야 합니다.)
- Firestore 데이터 추가 예제 (Python)
import firebase_admin
from firebase_admin import credentials
from firebase_admin import firestore
# Use the application default credentials
cred = credentials.ApplicationDefault()
firebase_admin.initialize_app(cred, {
'projectId': project_id,
})
db = firestore.client()
doc_ref = db.collection(u'annotations').document(u'some_image_file')
doc_ref.set({
u'x1': 30,
u'x2': 100,
u'y1': 200,
u'y2': 500,
u'class': 'car',
})
Data Warehouse
솔루션: BigQuery
Firestore에 저장된 어노테이션 데이터를 BigQuery로 추출하여, 데이터 과학자들께 데이터 분석 환경을 제공합니다. BigQuery를 오프라인 피처 스토어로 설정하여 이미지 데이터와 함께 딥러닝 모델 학습에 사용 할 수 있습니다.
비전 데이터셋 아키텍처 고도화
GCP에서 가장 기본적인 비전 데이터셋 아키텍처를 구성해 보았습니다. 이렇게 아키텍처를 구성하면 크게 두가지 문제에 직면하게 됩니다.
클라우드 비용 문제
비디오 데이터는 저장 장치 용량을 많이 차지하므로 수집되는 데이터가 많아질수록 클라우드 사용료가 큰 폭으로 증가하게 됩니다. 이런 문제를 해결하기 위해 아래와 같이 추출한 이미지 파일만 클라우드에 업로드하는 하이브리드 클라우드 방식으로도 아키텍처링 할 수 있습니다. 기존 GCP의 서비스와 동일한 동작을 하는 On-premise용 솔루션을 활용하여 클라우드 사용료를 절감 할 수 있습니다. On-premise로 일부 서비스가 이전됨에 따라 그만큼 인프라 관리 비용이 증가하는 점을 잊지마시기 바랍니다. (클라우드 사용료 > 인프라 관리 비용?)
Cloud Storage->MinIOCloud Pub/Sub->RabbitMQCloud Dataflow->Apache Beam

유사한 이미지 제거
자율주행 데이터셋을 수집하는 시나리오를 생각해보면, 1초마다 한 프레임을 추출하는 것은 자동차가 정지된 구간에는 유사한 이미지를 여러장 추출하여 라벨링 비용만 낭비할 가능성이 매우 큽니다. 능동적 학습 알고리즘을 적용하기 앞서 이미지 유사도를 검사하여 유사도가 높은 이미지는 샘플링 하지 않는 간단한 알고리즘으로도 샘플링 이미지 개수를 줄일수 있을 것 입니다.
파이썬에는 image-similarity-measures 패키지로 두 이미지의 유사도를 측정 할 수 있습니다. 아래는 두 이미지간의 유사도를 측정하는 파이썬 샘플 코드 입니다.
$ pip3 install image-similarity-measures
import cv2
import os
import image_similarity_measures
from sys import argv
from image_similarity_measures.quality_metrics import ssim
origin_img = argv[1]
second_img = argv[2]
test_img = cv2.imread(origin_img)
ssim_measures = {}
scale_percent = 100 # percent of original img size
width = int(test_img.shape[1] * scale_percent / 100)
height = int(test_img.shape[0] * scale_percent / 100)
dim = (width, height)
data_img = cv2.imread(second_img)
resized_img = cv2.resize(data_img, dim, interpolation = cv2.INTER_AREA)
ssim_measures = ssim(test_img, resized_img)
print(f"Image similaraty is {ssim_measures}")
$ python similaraty.py /tmp/sample-15s/0.jpg /tmp/sample-15s/406.jpg
Image similaraty is 0.7200022681160081
정리
처음 이 글을 작성할 때는 기본은 지키되 최대한 단순한 아키텍처를 제시하고 예제를 추가하려고 했습니다. 그 기본에 해당되는 부분이 생각보다 많네요. 인프라 코드 작성하고, Dataflow로 데이터 파이프라인 예제 만드는데 아직 부족한 점이 많아서 시간이 많이 걸렸습니다. 특히, Apache Beam은 이번에 처음 써보았는데 꽤나 진입 장벽이 있어서 어려웠습니다. (Apache Beam 고수 분들의 많은 피드백 부탁드립니다.)
이 글을 작성하면서 만든 vision-dataset-sample-infra 저장소는 Label Studio와 같은 오픈 소스 라벨링 툴과 연동해서 사용 할 수 있도록 시간날때 업데이트 할 예정입니다. BigQuery와 연동하여 데이터 분석 환경 제공하고, Vertex AI와 연동해서 ML 파이프라인도 붙이면 End-to-end 완성이네요! 기회가 된다면 이런 데이터 분석 환경과 MLOps 인프라도 추가 해 보겠습니다. (보장은 못드립니다. 바쁘면 안할지도…)