- 원본 기사> MLOps Architecture Guide
성공적인 머신러닝 프로젝트는 작동하는 앱을 배포하는 것만이 아닙니다. 긍정적인 비즈니스 가치를 제공하고 이를 지속적으로 유지하는 것입니다.
많은 머신 러닝 프로젝트를 수행하다 보면, 일부는 개발 중에는 잘 작동하지만 프로덕션에는 도달하지 못하는 것을 발견합니다. 다른 프로젝트는 프로덕션 단계에 있긴 하지만 사용자 요구에 맞게 확장이 안됩니다. 또 다른 프로젝트는 규모가 커진 후에는 너무 많은 비용이 들어서 수익을 창출하지 못합니다.

기존 소프트웨어에는 DevOps가 있고, 우리에게는 훨씬 더 중요한 MLOps가 있습니다. 프로젝트가 성공하려면 개발 및 프로덕션 워크로드에 적합한 최적의 MLOps 아키텍처가 필요합니다.
아래 이미지는 전체 MLOps 커뮤니티에서 가장 유명한 다이어그램일 수 있으며, 가장 많이 참조되는 ML 논문 중 하나에서 가져온 것입니다.

이 다이어그램은 프로덕션 레벨의 머신러닝 시스템에는 학습 알고리즘을 설계하고 코드를 작성하는 것 이상의 것이 있다는 것을 알려줍니다. 프로젝트에 가장 적합한 아키텍처를 선택하고 설계할 수 있다는 것은 종종 머신러닝 실험과 운영간의 차이를 메우는 것이며, 궁극적으로 ML 시스템의 숨겨진 기술적 부채를 갚는 것입니다.
이 기사에서는 다음을 배우게 됩니다:
- 일반적인 학습과 서빙 아키텍처 패턴
- Best MLOps 아키텍처 선정을 위한 뉴스 기사 추천 시스템 활용 사례
- ML 워크로드에 맞는 자체 MLOps 아키텍처를 선택하고 설계할 때 따라야 할 모범 사례 및 설계 원칙
이 기사 말미에는 비즈니스 문제가 주어지면 관련된 최적의 MLOps 아키텍처를 찾아내는 도전 과제도 제시합니다. 즐거운 시간을 보내시길 바라며, 바로 시작 하겠습니다!
프로덕션 레벨 머신러닝 시스템의 현실
머신러닝 프로젝트의 작업들을 생각해보면 다음과 같은 매우 상세한 워크플로우가 될 수 있습니다:

사실, 이와 같은 워크플로를 사용하여 이미 모델을 개발했으며 모델을 배포하고 성능 저하, 확장성, 속도, 유지 관리등과 같은 프로덕션 문제에 대해서만 대비하고자 할수도 있습니다.
실험과 개발을 넘어서 이후 과정을 고려하면 프로젝트를 철저히 처음부터 재검토를 해야 할 수도 있습니다. 즉, 솔루션을 현업에서 운영하기 위한 적절한 아키텍처를 선택하는 것부터 시작해야 합니다.
유명한 “Hidden Technical Debt in Machine Learning Systems” 논문에 나와 있듯이 일반적인 수준에서 머신 러닝 시스템을 운용하려면 복잡한 아키텍처가 필요합니다.
사용자에게 실시간으로 서비스를 제공하는 머신러닝 프로젝트의 경우 아키텍처는 어떤 모습이어야 한다고 생각하시나요? 무엇을 고려해야 할까요? 무엇을 설명해야 할까요?
아래는 프로젝트에 적합한 아키텍처를 찾을 때 볼 수 있는 복잡한 그림입니다 (복잡해 보이는 아키텍처이지만 지속적인 가치를 제공하는 프로덕션 등급 머신러닝 시스템을 구축하는 데 필요한 모든 것을 고려하지 않고 있습니다).

고려할 사항이 참 많네요! 보시다시피 시스템의 머신러닝(ML) 섹션과 시스템 운영(Ops) 섹션이 있습니다. 둘 다 함께 머신러닝 시스템의 아키텍처를 정의합니다.
MLOps의 일반적인 아키텍처 패턴에서 아키텍처 변경은 ML 단계와 Ops 단계에서 발생하며 문제와 데이터에 따라 다양한 개발 및 배포 패턴을 가질 수 있습니다. 다음 섹션에서는 ML 시스템의 일반적인 MLOps 아키텍처 패턴을 살펴보겠습니다.
일반적인 학습과 서빙 아키텍처 패턴
위의 머신러닝 시스템의 (상당히) 복잡한 표현에서 보았듯이 MLOps는 단순히 머신러닝과 운영이 혼합되어 인프라와 리소스 위에서 실행되는 것입니다.
MLOps의 아키텍처 패턴은 학습 및 서빙 설계에 관한 것입니다. 데이터 파이프라인 아키텍처는 종종 학습 및 서빙 아키텍처와 긴밀하게 결합됩니다.
머신러닝 개발/학습 아키텍처 패턴
학습 및 실험 단계에서 아키텍처 결정은 수신하는 입력 데이터와 문제 유형에 따라 결정되는 경우가 많습니다.
예를 들어, 프로덕션에서 입력 데이터가 자주 변경되는 경우 동적 학습 아키텍처(dynamic training architecture)를 고려할 수 있습니다. 입력 데이터가 거의 변경되지 않는 경우 정적 학습 아키텍처(static training architecture)를 고려할 수 있습니다.
동적 학습 아키텍처
이 경우 프로덕션에서 항상 변화하는 데이터 분포에 대해 모델을 재학습하여 모델을 지속적으로 업데이트합니다. 수신된 입력과 전반적인 문제 범위를 기반으로 하는 3가지 아키텍처가 있습니다.
1. 이벤트 기반 학습 아키텍처 (push-based)

데이터 웨어하우스로의 데이터 스트리밍와 같은 특정 이벤트로 다음과 같은 트리거 구성 요소가 켜지는 이벤트 기반 시나리오에 대한 학습 아키텍처:
- 워크플로우 오케스트레이션 도구(데이터 웨어하우스, 데이터 파이프라인 및 스토리지 또는 프로세싱 파이프라인에 작성된 기능 간의 워크플로우와 상호 작용을 조정하도록 지원)
- 또는 메시지 브로커(데이터 작업과 교육 작업 간의 프로세스를 조정하는 데 도움이 되는 중간자 역할)입니다.
스트림 분석 또는 온라인 서빙을 위해 IoT 장치의 실시간 데이터를 지속적으로 학습하도록 하려면 이 기능이 필요할 수 있습니다.
2. 오케스트레이션된 풀 기반 (pull-based) 학습 아키텍처

일정 간격으로 모델을 재학습해야 하는 시나리오에 대한 학습 아키텍처. 데이터는 웨어하우스에서 대기하고 있으며, 워크플로우 오케스트레이션 도구를 사용하여 추출 및 처리를 예약하고, 새로운 데이터에 대한 모델의 재학습을 실시합니다. 이 아키텍처는 특히 사용자가 계정에 로그인할 때 미리 계산된 추천 사항을 제공하는 콘텐츠 추천 엔진(노래 또는 기사용)과 같이 실시간 점수가 필요하지 않은 문제에 유용합니다.
3. 메시지 기반 (message-based) 학습 아키텍처

이러한 학습 아키텍처는 지속적인 모델 학습이 필요할 때 유용합니다. 예를 들어:
- 다른 소스(모바일 앱, 웹 상호 작용 및/또는 기타 데이터 저장소 등)에서 새로운 데이터가 도착합니다.
- 데이터 서비스는 데이터 웨어하우스에 데이터가 들어오면 메시지 브로커에게 메시지를 푸시하도록 메시지 브로커를 구독합니다.
- 메시지 브로커는 데이터 웨어하우스에서 데이터를 추출하기 위해 데이터 파이프라인으로 메시지를 보냅니다.
데이터 변환이 완료되고 데이터가 스토리지에 로드되면 메시지 브로커로 다시 메세지를 보내 데이터 스토리지에서 데이터를 로드하고 학습 작업을 시작하라는 메시지를 학습 파이프라인에 보냅니다.
기본적으로 데이터 서비스(데이터 파이프라인)와 학습 서비스(학습 파이프라인)를 단일 시스템으로 결합하여 각 작업에서 지속적으로 학습이 되도록 합니다. 예를 들어, 실시간 트랜잭션(부정 탐지 애플리케이션)에서 모델을 업데이트 하는 경우 이 학습 아키텍처가 필요할 수 있습니다.
또한 사용자가 학습 파이프라인 서비스로 요청을 전송하여 사용 가능한 데이터에 대한 학습을 시작하고 모델 데이터(학습 보고서)를 작성하는 사용자 트리거 (user-triggered) 학습 아키텍처로 사용할 수도 있습니다.
정적 학습 아키텍처
데이터 분포가 오프라인에서 훈련된 것과 크게 다르지 않은 문제에 대해 이 아키텍처를 고려하십시오. 이와 같은 문제의 예로 대출 승인 시스템을 들 수 있습니다. 대출 승인 또는 거부 여부를 결정하는 데 필요한 속성이 점진적인 분포 변경을 거치고 팬데믹과 같은 드문 경우에만 갑작스러운 변경이 발생합니다.
다음은 정적 학습을 위한 레퍼런스 아키텍처입니다. 한 번 학습하고 가끔씩 재학습합니다.

서빙 아키텍처
서빙 아키텍처는 매우 다양합니다. 프로덕션 환경에서 모델을 성공적으로 운영하려면 단순히 서비스를 제공하는 것 이상입니다. 또한 프로덕션 환경에서 모니터링, 통제(governing) 및 관리해야 합니다. 서빙 아키텍처는 다를 수 있지만 항상 이러한 측면을 고려해야 합니다.
서빙 아키텍처는 비즈니스 컨텍스트와 요구 사항에 따라 선택해야 합니다.
일반적인 운영 아키텍처 패턴
배치 아키텍처 패턴
이것은 프로덕션에서 검증된 모델을 제공하는 데 사용할 수 있는 가장 간단한 아키텍처입니다. 기본적으로 모델은 오프라인에서 추론을 수행하고 주문형(on-demand) 서비스를 제공할 수 있는 데이터 저장소에 결과를 저장합니다.
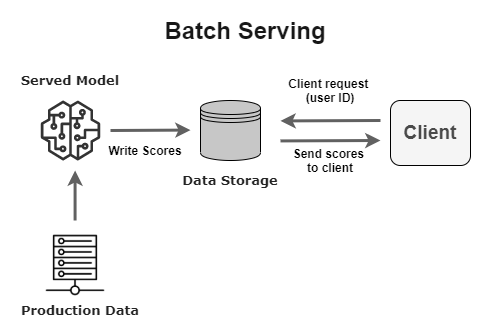
요구 사항에 몇 초 또는 몇 분 안에 클라이언트에게 추론 결과를 제공하지 않아도 되면 이러한 종류의 서빙 패턴을 사용할 수 있습니다. 일반적인 사용 사례는 콘텐츠 추천 시스템(사용자가 계정에 로그인하거나 애플리케이션을 열기 전에 추천을 미리 계산함)입니다.
온라인/실시간 아키텍처 패턴
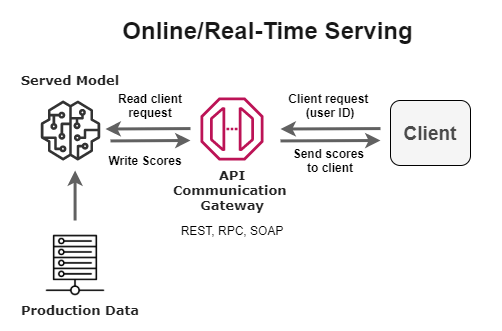
매우 최소한의 지연(몇 초 또는 몇 분 이내)으로 사용자에게 모델 추론 결과를 제공해야 하는 시나리오가 있습니다. 사용자가 요청할 때 실시간 추론을 제공하기 위한 온라인 서빙 아키텍처를 고려할 수 있습니다.
이 패턴에 맞는 사용 사례의 예는 거래가 완전한 처리를 거치기 전에 사기를 감지하는 것입니다.
다음과 같은 서빙 아키텍처를 살펴보는 것도 시간을 할애할만한 가치가 있습니다:
- 준 실시간(Near real-time) 서빙 아키텍처 - 개인화 사용 사례에 유용합니다.
- 임베디드 서빙 아키텍처 – 데이터와 모델이 로컬 또는 단말 장치(예: 휴대폰, 마이크로 컨트롤러)에 유지되어야 하는 사용 사례에 사용됩니다.
일반적인 MLOps 아키텍처 패턴을 보았으므로 이제 구현해 보겠습니다!
프로젝트에 “최적의” MLOps 아키텍처를 선택하는 방법
다른 제품이나 솔루션과 마찬가지로, 설계할 때 적절한 설계를 고안하는 것은 문제에 따라 매우 다릅니다. 유사한 문제가 아키텍처에 약간의 차이만 있을 수 있다는 것을 종종 발견할 수 있습니다. 그래서 “최고”는 매우 주관적일 수 있다는 것을 저는 이 기사에서 분명히 말하고 싶습니다. 제가 “최고의” 아키텍처라고 정의하는 것은 다음과 같습니다:
- 최종 사용자의 요구 사항을 중심으로 설계되었습니다.
- 프로젝트의 비즈니스 성공을 위해 필요한 프로젝트 요구사항을 고려합니다.
- 템플릿 모범 사례, 원칙, 방법론 및 기술을 준수합니다. 모범 사례 및 설계 원칙을 위해 지금까지 가장 일반화 가능한 템플릿인 Machine Learning Lens – AWS Well-Architected Framework practices 관행을 참조했습니다.
- 견고한 도구와 기술로 구현됩니다.
또한 MLOps 성숙도 수준에 따라 이들 중 일부가 적용되거나 적용되지 않을 수 있으므로 아키텍처 선택에 있어 훨씬 더 많은 주관성을 갖게 될 것입니다. 그럼에도 불구하고, 저는 시스템 운영 비용과 MLOps 성숙도를 감안하여 프로젝트에 대한 자세한 내용을 설명하려고 했습니다.
일관성을 유지하기 위해 프로젝트 활용 사례는 MLOps의 네 가지 요소를 고려합니다.
- 프로덕션 모델 배포
- 프로덕션 모델 모니터링
- 프로덕션 환경에서의 모델 거버넌스
- 모델 라이프사이클 관리(재학습, 리모델링, 자동화된 파이프라인)
이러한 아키텍처에 대해 생각하는 방법을 보여드리기 위해 다음과 같은 템플릿을 사용합니다:
- 문제 분석: 목적이 무엇입니까? 무슨 비지니스에 관한 것 인가요? 현재 상황? 제안된 ML 솔루션? 프로젝트에서 데이터 사용이 가능한가요?
- 요구 사항 고려: 성공적인 프로젝트 실행에 필요한 요구 사항 및 스펙은 무엇입니까? 요구 사항은 전체 애플리케이션이 수행하기를 원하는 것이며 스펙은 이 경우 데이터, 실험 및 생산 모델 관리 측면에서 애플리케이션이 수행하기를 원하는 방식입니다.
- 시스템 구조 정의: 방법론을 통해 아키텍처 백본/구조를 정의합니다.
- 구현 결정: 권장되는 견고한 도구 및 기술로 구조를 채웁니다.
- 검토: AWS Well-Architected Framework(Machine Learning Lens) 관행을 사용하여 이러한 아키텍처가 “최고”인 이유를 검토합니다.
AWS Well-Architected Framework (Machine Learning Lens)의 우수한 설계 원칙 적용
AWS에서 개발한 Well-Architected 솔루션의 5대 요소를 채택합니다. 우수한 설계 원칙 및 모범 사례의 표준 프레임워크를 사용하여 최적의 비즈니스 가치를 가진 솔루션을 구축하는 데 도움이 됩니다:
- 운영 효율성: 비즈니스 가치를 제공하고 지원 프로세스 및 절차를 지속적으로 개선하기 위해 프로덕션에서 모델을 운영하고, 모니터링하고, ML 시스템에 대한 통찰력을 얻는 기능에 중점을 둡니다.
- 보안: 리스크 평가 및 완화 전략을 통해 비즈니스 가치를 제공하는 동시에 정보, 시스템 및 자산(데이터)을 보호하는 기능에 초점을 맞춥니다.
- 신뢰성: 인프라 또는 서비스 중단으로부터 복구하고, 수요를 충족하기 위해 컴퓨팅 리소스를 동적으로 확보하며, 잘못된 구성 또는 일시적인 네트워크 문제와 같은 운영 중단을 완화하는 시스템의 기능에 초점을 맞춥니다.
- 성능 효율성: 요구사항을 충족하기 위해 컴퓨팅 리소스를 효율적으로 사용하고 수요 변화와 기술의 발전에 따라 효율성을 유지하는 방법에 초점을 맞춥니다.
- 비용 최적화: 비즈니스의 투자 수익률을 극대화하기 위해 비즈니스 성과를 달성하고 비용을 최소화하는 비용 인식(cost-aware) ML 시스템을 구축 및 운영할 수 있는 기능에 초점을 맞춥니다.
머신러닝을 위한 Well-Architected Framework 아키텍처 설계 원칙 요약
아키텍처를 계획할 때 유의해야 할 5가지 주요 설계 원칙을 바탕으로 요약 표를 작성했습니다.
| Well-Architected 기준 | ML 시스템의 설계 원칙 |
|---|---|
| 운영 효율성 | - 교차 기능(cross-functional) 팀을 구성합니다. - ML 워크플로 초기에 종단간 아키텍처 및 운영 모델을 식별합니다. – ML 워크로드를 지속적으로 모니터링하고 측정합니다. – 모델 재학습 전략 수립: 자동화? 인간의 개입? - 머신러닝 입력 및 아티팩트의 버전을 지정합니다. - 머신러닝 배포 파이프라인을 자동화합니다. |
| 보안 | – ML 시스템에 대한 액세스를 제한합니다. – 데이터 거버넌스를 보장합니다. – 데이터 계보를 적용합니다. – 규정 준수를 시행합니다. |
| 신뢰성 | – 자동화를 통해 모델 입력에 대한 변경 사항을 관리합니다. – 한 번 학습하고 여러 환경에 배포합니다. |
| 성능 효율성 | – ML 워크로드에 맞게 컴퓨팅을 최적화합니다. – 모델의 지연 시간 및 네트워크 대역폭 성능 요구사항을 정의합니다. – 시스템 성능을 지속적으로 모니터링하고 측정합니다. |
| 비용 최적화 | – 관리형 서비스를 사용하여 소유 비용을 절감합니다. – 작은 데이터 세트로 실험합니다. – 적절한 규모의 학습 및 모델 호스팅 인스턴스. |
정의된 프로젝트에 대한 최적의 MLOps 아키텍처
우리는 각 프로젝트에 대한 아키텍처를 선택하는 과정을 통해 생각해 볼만한 아래와 같은 프로젝트를 선정했습니다. 시작해 보겠습니다.
프로젝트: 뉴스 기사 추천 시스템

컨텐츠 추천 시스템은 사용자가 플랫폼에 더 많은 비용을 지출하도록 기업이 관련 컨텐츠에 계속 관여할 수 있도록 도움을 줍니다. 특히 항상 고객 참여를 높이는 것이 목표였던 미디어에서는 더욱 그렇습니다.
시나리오
뉴스 기사 추천 회사인 우리 회사의 비즈니스 분석가는 최근 고객 이탈이 많다는 것을 깨달았습니다. 상황을 분석한 결과, 사용자가 플랫폼에 참여하지 않는다고 느껴 구독을 유지하지 않거나 다른 미디어 플랫폼으로 넘어간다는 결론을 내렸습니다. 우리는 비즈니스 분석 팀 및 일부 충성 고객과 긴밀히 협력했으며, 사용자를 위해 플랫폼을 개인화할 수 있을 때까지 사용자가 이탈하거나 더 심하게는 완전히 이탈하는 것이 지속된다는 사실을 알게 되었습니다.
이를 위한 첫 번째 단계는 독자가 로그인할 때 읽고 이메일로 보낼 가능성이 높은 뉴스 기사를 추천하는 기존 제품과 통합되는 기능을 구축하는 것입니다.
경영진은 범위를 늘리기 전에 시스템을 구축하고 선택된 수의 사용자를 대상으로 테스트해야 한다는 조건에 동의합니다.
…그렇게 여기까지 왔습니다. 이제 무엇을 할까요? 자, 아키텍처링을 시작하겠습니다!
문제 분석
비즈니스 이해
- 이 비즈니스는 현재 3개 지역(라틴 아메리카, 아프리카 및 북아메리카)에서 521,000명 이상의 유료 고객을 보유하고 있습니다.
- 그들은 유료 구독자에게 서비스를 제공하기 위해 다양한 출판물의 기사를 선별합니다.
- 사용자가 플랫폼을 처음 방문하고 무료 평가판을 활성화하면 관심 있는 기사의 관련 카테고리를 선택하라는 메시지가 표시됩니다.
- 그들은 해당 카테고리의 최신 기사를 받고 기사와의 상호 작용과 애플리케이션 또는 웹 사이트의 페이지에 머무는 시간에 대한 데이터를 수집합니다.
사업 목표는 무엇입니까? 구독자가 계속 서비스를 구독할 수 있도록 주어진 로그인 세션에 대해 가장 관련성이 높은 기사를 추천하여 구독자의 참여를 개선합니다.
비즈니스 지표는 무엇입니까? 사용자가 기사에 소비하는 시간(분)의 증가입니다. 클릭수보다 이 매트릭을 사용한 이유는 사용자가 기사를 클릭하는지 여부에 영향을 줄 수 있는 많은 외부 요인이 있기 때문입니다. 헤드라인에서 표지 사진 또는 하위 헤드라인, UI 디자인 등.
프로젝트의 범위는 무엇입니까?
- 채택할 수 있는 템플릿이 있기 때문에 프로젝트 범위의 위험도가 낮습니다.
- 이 프로젝트는 사용자의 경험이 직접적으로 영향을 받는 외부 프로젝트입니다.
- 현재로선 약 ~15,000명 내외의 선택된 사용자들로만 프로젝트를 구축하고 테스트하고 있으므로 비즈니스에서 프로젝트를 적절히 제어하고 영향을 관리할 수 있습니다.
- 비즈니스 이해 관계자는 또한 ~15,000명의 사용자를 대상으로 테스트하는 동안 전체 시스템을 온프레미스에서 실행하도록 요청했으며 전체 프로젝트 비용이 얼마인지 최종 보고서가 나오면 이에 대해 보다 명확한 논의를 할 수 있습니다.
- 간혹 가짜 뉴스 기사도 있으니 시스템 관리시 주의가 필요합니다.
기술적 고려사항
- 팀: 우리는 현재 두 명으로 구성된 팀입니다. 저와 데이터 엔지니어는 이 범위에 매우 적합합니다. 우리는 각자 업무에 대한 스트레스를 줄일 수 있는 방법을 찾아야 합니다! 또한 사내 시스템 및 프라이빗 클라우드 플랫폼용 애플리케이션 및 내부 시스템을 쿠버네티스 클러스터에 이미 구축한 조직의 Ops 팀에 액세스할 수 있습니다.
- 하드웨어/인프라 프로비전: 프로젝트를 실행하기 위해 온프레미스에서 자체 리소스를 프로비저닝해 왔습니다. 또한 도구를 선택할 수 있는 무료 이용권도 제공받았습니다. 특별히 운영 팀에 기존 도구들이 있는 경우에는 그렇지 않을 수 있습니다.
데이터 이해
- 사용 가능한 과거 데이터에는 기사의 콘텐츠 세부 정보, 콘텐츠 카테고리, 사용자가 특정 기사에서 보낸 시간, 사용자의 고유 식별자, 기사를 방문한 총 횟수가 포함됩니다.
- 다양한 출판물로부터 매일 ~144,000개의 새로운 기사가 나올 것으로 예상됩니다.
- 기사에는 링크, 카테고리, 출시 날짜, 출판 이름 및 기타 메타데이터가 포함되어 있습니다.
요구사항 고려
시스템 요구 사항을 고려할 때 다음과 같은 몇 가지 사항을 이해해야 합니다:
- 무엇이 좋은 사용자 경험을 보장합니까? 사용자는 실제 사용자일 수도 있고 백엔드 서비스와 같은 소비자(다운스트림 서비스)일 수도 있습니다.
- 좋은 사용자 경험을 구현하기 위해 솔루션의 어떤 부분이 가장 중요합니까?
- 사용자에게 첫 번째 버전을 제공하고 피드백을 수집하기 위해 최대한 빨리 구현할 수 있는 최소 가치 제품(MVP, Minimum Valuable Product)은 무엇입니까?
프로젝트에 대한 요구 사항을 마련하기 위해 Voleere의 요구 사항 스펙 템플릿을 필요에 맞게 조정할 수 있습니다. 저는 Michael Perlin이 만든 Github의 이 체크리스트의 질문을 요구 사항으로 사용했습니다.
요구 사항: 이 서비스는 모바일 애플리케이션이나 웹사이트 홈페이지를 통해 로그인 세션에 대한 관심도에 따라 사용자가 읽을 수 있는 상위 10개의 기사를 추천해야 합니다.
이제 ML 시스템의 각 구성 요소에 대한 요구사항 스펙를 자세히 살펴보겠습니다.
데이터 수집 및 기능 관리 스펙
- 다양한 소스에서 기사를 가져오기 때문에 프로덕션 데이터를 데이터 파이프라인으로 쉽게 수집할 수 있도록 데이터 액세스를 데이터 웨어하우스로 중앙 집중화하는 것이 좋습니다.
- 머신러닝 모델을 오프라인으로 재학습하기 위해 프로덕션 데이터에서 추출한 변환된 피처 값을 저장하기 위한 피처 스토어가 필요합니다.
- 감사, 디버깅 또는 기타 목적을 위해 데이터 계보를 적절하게 추적할 수 있도록 데이터 버전 관리도 해야 합니다.
- 또한 자동화된 워크플로우가 기대하는 대로 데이터 품질을 모니터링해야 합니다.
실험 관리 및 모델 개발 스펙
- 학습은 사용자에 대한 기존 데이터와 이전 기사와의 상호 작용으로 오프라인에서 수행되어야 합니다.
- 오래된 모델과 궁극적으로 오래된 추천 사항을 피하기 위해 릴리스된 기사의 신선도를 보완할 동적 학습 아키텍처가 필요합니다.
- 실험의 세부 정보와 학습 실행의 메타데이터를 저장할 모델 레지스트리가 필요합니다. 이를 통해 배포되는 모델과 데이터의 계보 추적도 가능합니다.
- 매일 새로운 기사가 쏟아지기 때문에 재학습 프로세스를 자동화 하기 위해 학습 파이프라인이 필요합니다.
- 예산이 한정되어 있기에 모델은 적절한 시간에 매일 학습해야 하며 하며, 대량의 새로운 기사 출판에서 모델 학습에 오랜 시간을 할애할 수 없으므로 학습 데이터의 양을 제한해야 할 수도 있습니다.
- 또한 학습 아키텍처에서는 모델 체크포인트를 활용하여 학습 및 재학습이 너무 오래 걸리지 않도록 할 수 있습니다(가급적이면 사용자가 로그인하는 시간이 가장 많은 시점부터 몇 시간 이내가 좋습니다).
프로덕션 모델 관리 스펙
-
배포 및 서빙 스펙
- 사용자가 플랫폼을 탐색하는 동안 실시간 추론을 제공할 필요가 없기 때문에 배치 추론 시스템이 유용할 것 같습니다. 추천은 오프라인으로 계산하여 데이터베이스에 저장되며 사용자가 로그인할 때 제공할 수 있습니다.
- 기존 시스템과 연동하기 위해 RESTful 인터페이스로 모델을 서빙 할 수 있습니다.
- 변경점으로 인하여 자동화된 파이프라인 실행이 실패하지 않도록 서빙 의존성 변경점 처리하는 것을 피해야 합니다.
- 성공적인 모델 평가 후 새 버전 모델을 지속적으로 배포하기 쉬워야 하며, 매일 모델 학습이 실행되는 것을 추적하기를 원합니다.
-
모델 모니터링 스펙
- 뉴스 이벤트가 매우 역동적이고 사용자의 읽기 동작도 불확실해질 수 있으므로 사용자가 오래된 추천을 받지 않도록 모델 드리프트를 실시간으로 모니터링해야 합니다.
- 단 하루만에 일반적으로 예상되는 것보다 신규 기사가 더 적을 수 있기에 데이터 품질 이슈를 모니터링해야 합니다. 또한 손상된 데이터를 고려합니다.
- 모델을 재학습하는 경우가 많기 때문에 모델이 실행되지 않을 때 학습 세부 정보를 감사하고 문제를 해결할 수 있도록 각 실행에 대한 학습 메타데이터를 추적해야 합니다.
- 파이프라인을 다루고 있으므로 파이프라인의 상태를 측정하기 위해 모니터링 구성 요소가 필요합니다.
- 모델 성능과 모델 드리프트를 측정하기 위해 한 사람이 기사에 소비하는 시간에 대한 Ground Truth 레이블을 수집해야 합니다.
- 모델 드리프트와 함께 데이터 드리프트를 모니터링하여 사용자 선호도 및 기사 피처의 변화를 포착해야 합니다.
- 모델이 지속적으로 업데이트되는지 확신 하기 위해 파이프라인이 실패할 경우 대시보드 뷰와 경보에서 보고서를 얻을 수 있어야 합니다.
-
모델 관리 스펙
- 이벤트를 기반으로 많은 수의 기사가 무작위로 들어오기 때문에, 일정에 따라 워크플로우를 실행하여 새로운 데이터에 대해 모델을 재학습하는 풀 기반(pull-based) 아키텍처를 설정할 수 있습니다.
- 재학습 및 재배포된 각 모델 버전에 대해 모델 버전 관리도 수행하여 재학습된 모델의 성능이 더 나쁠 경우 쉽게 롤백할 수 있습니다.
- 재학습은 피처 스토어에 있는 변환된 데이터로 수행됩니다.
-
모델 거버넌스 스펙
- 잘못된 정보를 감사할 수 있고 규제해야 하기 때문에 모델의 결정을 설명가능(explainable)해야 합니다.
시스템 운영 (Ops) 스펙
- 모델이 프로덕션 환경에서 실행될 수 있는 방법을 정의해야 합니다. 서비스가 서로 상호 작용하기 위한 기준은 무엇이며 이것이 전체 시스템의 작동을 어떻게 정의합니까? 기본적으로 최적의 시스템 운영을 위한 성능 요구 사항입니다.
- 추천 서비스와 백엔드 서버 간에 95% 서비스 수준 계약(SLA, Service Level Agreement).
- 수천 명의 사용자에게 데이터 저장소를 통해 일괄 추론을 제공할 때 낮은 서빙 지연시간 및 높은 처리량 서빙.
- 성공한 API 호출, 실패한 API 호출 및 타임아웃된 API 호출 수를 추적합니다.
- 학습 파이프라인과 전체 시스템은 I/O, CPU 및 메모리 사용량등의 리소스 측면에서 모니터링해야 합니다.
- 인프라는 모델과 런타임에 구애받지 않아야 합니다.
- 프로덕션 환경은 데이터 및 모델 파이프라인을 실행하는 동안 오류가 발생할 수 있는 의존성 변경이 자주 필요하지 않아야 합니다. 대부분 결정론적(deterministic)이어야 합니다.
- 시스템이 실패할 때 롤백 전략을 사용할 수 있기 때문에 재현 가능한(reproducible) 환경이 필요합니다.
- 의존성 변경으로 인한 충돌을 쉽게 디버깅할 수 있도록 모든 인프라 패키지의 버전을 올바르게 설정해야 합니다.
시스템 구조 정의
위에 나열된 목표, 요구사항 및 스펙을 기반으로 시스템에 대한 아래 구조를 만들 수 있습니다. 도구 또는 구현에 대한 언급이 전혀 없다는 것을 알 수 있습니다. 그렇습니다! 이것은 비즈니스 목표와 최종 사용자를 염두에 둔 시스템 설계에 관한 것입니다. 아키텍처를 설계할 때는 가능한 한 기술에 구애받지 않고 요구사항과 스펙에만 집중해야 합니다.

시스템의 구조는 비즈니스 목표에 기반한 요구사항과 스펙을 기반으로 합니다. 시스템 구조를 제대로 잡을 수 있게 되면, 이제 구현할 도구와 기술을 선택할 수 있습니다.
구성 요소 기반(component-based) 아키텍처라고도 하는 위와 같은 아키텍처 다이어그램 외에도 다이어그램의 각 섹션을 더 깊이 파고들어 중요한 것을 놓치지 않도록 않도록 해야 합니다. 또한 다음과 같은 다른 다이어그램도 고려해 보세요:
- 상태 및 시퀀스 다이어그램(State and sequence diagrams): 아키텍처의 사양(예: 데이터, 실험 및 생산 관리 단계)과 다양한 단계와 객체가 서로 상호 작용하는 방식을 보여주는 다이어그램. 여기에서 상태 다이어그램의 예를 참조하세요.
- 볼만한 다른 다이어그램은 활동 다이어그램(activity diagram)입니다.
짐작하셨겠지만, 이 아키텍처는 MLOps 성숙도 레벨 1에 있습니다.
그나저나, 이 구조는 여러분이 해결하려는 ML 문제와 전혀 무관합니다. 즉, 컴퓨터 비전 프로젝트를 수행하든 자연어 처리 작업을 수행하든 상관 없이 작동할 수 있음을 의미합니다. 여기에는 명백히 명시되어 있지만 일부 데이터 관리 스펙이 변경될 수도 있습니다.
구현 결정
구현 결정시 고려 사항
MLOps는 여전히 매우 초기 단계이기 때문에 앞서 언급드린것 처럼 효율적인 ML 시스템을 구축하려면 템플릿화된 모범 사례를 따르고 견고한 도구를 사용해야 합니다(오리지날 아이디어에 대해 Raghav Ramesh의 공로). 즉, 요구 사항 및 스펙에 따라 구조의 다양한 구성 요소를 구현하는 데 사용할 도구를 결정하는 동안 신중하게 결정해야 합니다.
현재로서는 구현하려는 구성 요소에 대해 충분히 견고한 도구를 찾는 것이 좋습니다. 수평 스택(데이터, 실험 및 모델 관리)을 포괄하고 기존 에코시스템과 통합이 용이하고 다른 환경 간에 쉽게 마이그레이션할 수 있는 단일 플랫폼이 바람직합니다. 고맙게도 MLOps 커뮤니티는 훌륭하며 이 웹사이트에서 MLOps용으로 선별된 전체 도구 목록을 찾을 수 있습니다.
MLOps 아키텍처를 구현하기 위한 도구(또는 “장난감” 😉)을 결정할 때 다음 사항을 고려해야 합니다:
- MVP가 얼마나 빨리 필요하고 MVP를 출시하려면 얼마나 걸리나요?
- 수행한 위험 평가의 결과는 무엇입니까? 데이터, 모델 및 전체 시스템 측면에서 플랫폼의 보안 요구 사항이 얼마나 중요합니까?
- 이 도구을 배우고 기존 도구 에코시스템과 통합하기가 어려울까요?
- (팀으로 일하는 경우) 팀에서 특정 도구 또는 도구 세트를 사용한 경험이 있습니까?
- 구독 또는 라이센스 비용(구매하는 경우), 호스팅 비용, 유지 관리 비용 등의 도구에 대한 비용은 프로젝트에 책정된 예산내에서 합리적인가요?
기본적으로 구현을 결정할 때 범위, 요구 사항, 위험 및 제약 조건(예: 비용, 이해관계자 회의론 등)을 기반으로 프로젝트에 가장 적합한 것을 선택하려고 합니다.
프로젝트로 돌아가서, 이 프로젝트는 다양한 견고한 도구를 사용하여 구성요소를 구현합니다. 현재 예산 제약과 프로젝트 범위 때문에 오픈 소스 솔루션도 고려해 보겠습니다. 인프라 고려사항에서 좀 더 발전해 나가겠습니다.
인프라 도구
- 인프라 결정부터 시작하겠습니다. 이를 위해, 우리는 전체 시스템이 어디에나 이식 가능하고 실행 가능한 것이 좋으며 모델에 구애받지 않아야 합니다.
- 스펙 면에서 합리적이고 오픈 소스이기 때문에 런타임 환경으로 쿠버네티스 엔진을 사용할 것 입니다.
- 쿠버네티스로 전체 시스템을 이식 가능하게 하면 필요할 경우 온프레미스 솔루션에서 클라우드 또는 하이브리드 솔루션으로 쉽게 마이그레이션할 수 있습니다.
- 예산 제약으로 인해 쿠버네티스를 사용하여 시스템 리소스 제한을 지정할 수 있으며 전체 시스템을 제한합니다. 또한 오픈 소스이며 내부 운영 팀이 이미 이에 대해 잘 알고 있습니다(“기술적 고려 사항” 섹션 참조).
- 보안 조치로 시스템 전체 액세스 제어를 위해 Kubernetes 확장을 사용할 수도 있습니다.
주의: 머신러닝에 k8s(Kubernetes)를 사용한다는 Kubeflow를 알고 있지만 지금은 모르는 척 합시다. 결국, 이것이 아키텍처의 최종 형태는 아니겠죠? 우리는 확실한 교훈을 얻고 나중에 아키텍처를 다시 볼 것입니다!
데이터 수집 및 피처 관리 도구
- 데이터 저장소는 구조화된 데이터를 위한 효율적인 오픈 소스 데이터베이스인 PostgreSQL을 채택할 것입니다. 또한 대부분의 관리형 솔루션은 일반적으로 PostgreSQL 및 MySQL을 기반으로 합니다.
- 또한 데이터 파이프라인이 필요하고 ETL(Extract, Transform, Load)을 작성하기 위해 Apache Beam을 사용할 것입니다.
- 데이터 파이프라인을 버전화하기 위해 GIT와 유사한 형태로 데이터셋 버전 관리 제공하는 오픈 소스 도구인 DVC(Data Version Control)를 사용합니다.
- 피처 스토어의 경우, Feast를 사용합니다. Feast는 오픈 소스이며 다른 저장소 도구(PostgreSQL)와 잘 통합됩니다.
실험 관리 및 모델 개발 도구
- 실험 관리를 위해 Neptune을 사용하여 모델 학습이 재현 가능하고 하드웨어 사용량(CPU 및 메모리 사용량)과 하이퍼 파라미터 값에 대한 필요한 메타데이터가 기록되어 쉽게 시각화하고 공유할 수 있습니다.
- Neptune은 또한 데이터 세트 버전 관리를 지원하고 모델이 학습된 특정 데이터 세트 버전을 추적하는 데 도움이 됩니다.
- 모델 개발을 위해 Python을 지원하는 프레임워크를 사용할 것입니다.
- 지금은 분산 학습을 수행할 스펙이 없으므로 일단 이 스펙은 남겨두겠습니다.
| 더보기 👉 기사 읽기: ML 실험 추적: 정의, 중요한 이유 및 구현 방법 👉 Neptune의 문서 살펴보기 |
프로덕션 모델 관리
1. 배포와 서빙 도구
- 배포용 모델을 패키징하기 위해 Docker를 사용합니다. 대부분의 플랫폼에서 지원되며, 온프레미스에서 실행되며, 쿠버네티스 내에서 관리할 수 있습니다. 이 프로젝트의 범위를 바라보는 타협이 없으므로 지금은 무료 버전으로도 충분합니다.
- API 프로토콜은 REST API이고 API 게이트웨이는 Kong Gateway를 사용할 것입니다. 이는 오픈 소스이며 쿠버네티스를 기본적으로 지원하며 온프레미스 환경에서 실행할 수 있습니다. 그리고 설정이 정말 쉽습니다!
- 모델 코드를 배포하기 위해 모든 프로젝트 코드가 비공개 GitHub 저장소에 있으므로 GitHub Actions를 사용합니다. 이를 통해 CI/CD 파이프라인도 사용할 수 있습니다. 호스팅은 온프레미스에서 무료이지만 개인 리포지토리의 무료 버전으로 충분한지 확인하기 위해 워크플로에 소요되는 시간(분)을 면밀히 모니터링합니다.
- 사용하는 프레임워크에 따라 모델을 서비스로 배포하는 데 사용할 서빙 도구를 고려할 것입니다. 우리는 지금 Flask나 FastAPI를 고려하고 있습니다. TensorFlow Serving을 살펴볼 수도 있겠지만 프로젝트 범위에 따라 위의 두 프레임워크 중 하나면 충분할 것 입니다.
2. 모니터링 도구
- 프로덕션 모델을 모니터링하기 위해 Prometheus와 Grafana의 완벽한 오픈 소스 조합을 사용합니다. Prometheus는 모니터링 데이터를 수집하기 위한 시계열 데이터베이스이며 Grafana는 모니터링되는 메트릭과 구성 요소를 차트에 시각화합니다. ML 모니터링 서비스로 변환하는 방법에 대한 매우 유용한 문서와 튜토리얼이 있습니다. 그것들은 매우 견고한 도구입니다.
- 또한 지속적인 모니터링 및 식별 가능성을 위해 Prometheus의 Alertmanager를 사용하여 당사 도구의 서비스 보고서 외에 알림을 보내는 것도 고려할 것입니다.
- 시스템 메트릭을 로깅할 때는 ELK 스택의 Elasticsearch을 사용합니다. Elasticsearch은 오픈 소스이며 널리 사용되는 플랫폼 모두 지원되기 때문입니다.
- 또한 시스템에 대한 API 호출에 대한 상세 내역(성공 호출, 실패 호출 및 시간 초과 호출)을 로깅할 수 있습니다.
- 또한 시스템이 수행하는 트랜잭션의 양, 처리한 요청 수, 데이터베이스에서 유사도 점수를 포함한 상위 N개(클라이언트의 요청에 따라 상위 5개 또는 상위 10개) 추천 기사를 제공하는 데 걸린 시간 측면에서 핵심 스펙인 처리량을 추적할 수 있습니다.
3. 모델 관리 도구
- Neptune.ai은 모든 학습 실행에 대한 모델 레지스트리로 사용할 수 있습니다. 모델 버전은 계통 추적성을 위해 기록할 수 있습니다.
- 워크플로우 스케줄링 및 오케스트레이션의 경우 가장 널리 사용되는 오케스트레이션 툴인 Apache Airflow을 사용합니다.
4. 모델 거버넌스 도구
구현 선택은 여기까지입니다. 이 솔루션은 시스템 구조를 기반으로 구축되었으며 계획 단계에서 정의한 요구사항과 범위에 부합한다는 것을 알 수 있습니다. 이제 앞에서 살펴본 AWS Well-Architected Framework(머신 러닝 렌즈)를 사용해 보겠습니다.
Well-Architected Framework에 따른 아키텍처 검토
운영 효율성
- ML 워크플로 초기에 종단 간 아키텍처와 운영 모델을 식별할 수 있었습니다.
- 머신러닝 워크로드에 대한 지속적인 모니터링과 측정을 통합했습니다.
- 문제 설명, 요구사항 및 예산을 기반으로 모델 재학습 전략을 수립했습니다.
- 학습 파이프라인에서 모델 및 아티팩트의 버전 관리를 위한 구성 요소를 구현했습니다.
- 자동화된 워크플로우와 학습 코드를 워크플로우 도구로 커밋하여 모델의 지속적인 통합 및 배포를 보장합니다.
보안
- 지금까지 우리는 데이터 및 모델 계보 추적 기능만 적용했습니다. 이는 좋은 추가 기능입니다.
- 구현 중에 사용하는 대부분의 도구는 보안 모범 사례를 따를 수 있도록 액세스 수준 제어를 제공합니다.
- 프로덕션 환경에 대한 운영 보안, 재해 복구, 전송 중 및 유휴 상태의 스트리밍 데이터 소스의 데이터 암호화와 같은 다른 방법을 계획할 수 있습니다.
- 보안 조치를 감사하는 것도 이 아키텍처에서 할 수 있습니다.
신뢰성
- 지금까지 우리는 시스템을 런타임에 구애받지 않고 모델을 한 번 학습하고 어디에서나 실행할 수 있었습니다.
- Apache Beam 및 Apache Airflow로 수행해야 할 한 가지는 데이터 파이프라인으로 수집되는 데이터에 대한 테스트 가능성을 구현하는 것입니다.
성능 효율성
- 쿠버네티스는 워크로드를 실행하기 위해 리소스를 제한할 수 있으며 자동으로 워크로드를 확장하여 ML 워크로드에 대한 리소스를 최적화합니다.
- Prometheus 및 Grafana로 시스템 메트릭을 모니터링하면 모델별 리소스 사용량을 추적할 수 있습니다.
- 이 모니터링 도구를 사용하면 시스템 메트릭을 통해 시스템 성능을 지속적으로 모니터링하고 측정할 수 있습니다.
비용 최적화
- 이 아키텍처는 크거나 작은 모든 크기의 데이터 세트 스트리밍을 허용합니다. 항상 다양한 크기로 실험하는 것을 고려할 수 있습니다.
- 대부분의 도구는 현재 온프레미스용이지만 런타임 환경은 이식 가능하기 때문에 항상 관리형 인프라로 이동할 수 있습니다.
- 쿠버네티스용 YAML 파일에 지정하여 ML 워크로드에 사용되는 리소스를 제한할 수 있습니다.
도전 과제
도입부에서 도전 과제를 드린다고 했었습니다. 자, 여기 있습니다:
익일 주문 처리를 보장하는 비즈니스를 위해 주문 관리 서비스와 통합해야 하는 사기 탐지 시스템을 어떻게 구축하시겠습니까?
원하는 대로 비즈니스를 자유롭게 정의할 수 있지만 이전 프로젝트보다 더 큰 범위를 생각하고 싶을 수도 있습니다.
이 과제를 해결하려면 이 기사 끝에 있는 “프로젝트에 가장 적합한 MLOps 아키텍처를 선택하기 위한 리소스” 섹션에서 제시한 아키텍처를 참조하십시오. 행운을 빕니다!
이제 여러분의 차례입니다. 프로젝트에 가장 적합한 MLOps 아키텍처를 어떻게 선택해야 할까요?
프로젝트에 가장 적합한 아키텍처를 선택하려면 다음을 수행하는 것이 좋습니다:
- 프로젝트에 필요한 요구사항, 범위 및 제약조건을 명확하게 이해하고 명확하게 설명하십시오. 시작하는 데 도움이 되는 Michael Perlin의 3부작 비디오 시리즈가 있습니다. 다른 리소스는 참고문헌 및 리소스 섹션에서 찾을 수 있습니다. 요구 사항에는 비즈니스 목표와 좋은 사용자 경험을 구성하는 요소가 명확하게 명시되어 있어야 합니다.
- 요구 사항에 따라 시스템 구조를 설계하고 이 시점에는 시스템 구조에 맞는 구현이나 기술을 생각하지 마십시오. 주요 목표는 이전 단계의 요구 사항에 따라 시스템 구조를 정의하는 것입니다. 저는 다른 사람들이 이 시점에서 어떤 일을 해왔는지, 어떤 일을 하고 있는지 자신의 시스템 구조/아키텍처 측면에서 살펴보는 것을 추천합니다. (이 문서의 끝부분에 있는 리소스 섹션에서 배울 수 있는 아키텍처 센터에 링크했습니다.)
- 이제 구현을 결정할 때입니다! 도구와 기술을 선택할 때 사용할 ML 파이프라인의 모든 단계에 대해 충분히 견고한지 확인하십시오. 모니터링 도구인 경우 확장 가능하고 필요한 모든 기능이 있는지 확인하십시오.
- 마지막으로, AWS의 Machine Learning Well-Architected Framework 설계 원칙과 모범 사례 또는 다른 좋은 템플릿을 사용하여 아키텍처 타당성을 보여주십시오.
아키텍처는 기반만 형성하고 ML 시스템이 구축되어야 하는 방법에 대한 경로를 제공합니다. 구현 상자에 갇혀서는 안 되며, ML 시스템을 반복적으로 구축할 때 수정할 수 있다는 점을 이해해야 합니다.
이것이 애자일 ML 소프트웨어 구축이 필요한 이유입니다. 따라서 문제를 신속하게 발견하거나 구현을 지원하고 필요한 기간 동안 가장 최적의 ML 시스템을 제공하는 데 도움이 될 수 있는 더 나은 도구 또는 플랫폼을 확인할 수 있습니다.
유용할 수 있는 몇 가지 팁…
- 확립된 모범 사례 준수 + 견고한 도구 및 구현 + 최적의 솔루션을 반복적으로 구축하기 위해 최대한 빨리 MVP를 공개합니다.
- 머신러닝 프로젝트 라이프사이클 초기에 MLOps 아키텍처를 고려하고 계획해야 합니다. 이렇게 하면 활동을 조정하고 개발 및 운영의 사각지대를 찾을 수 있습니다.
- 다른 사람들에게 아키텍처를 “볶을(roast)” 기회를 주십시오. MLOps 커뮤니티 슬랙 채널에서 자주 발생하는 일은 다른 사람들이 아키텍처의 공개 버전을 업로드하여 다른 사람들이 이를 비판하고 유용한 피드백을 제공할 수 있는 기회를 제공하는 것입니다. 그러한 커뮤니티에 가입하고 다른 실무자들과 상호 작용하고 시스템이 어떤 모습이어야 한다고 생각하는지 디자인할 수 있습니다. 필요한 요구사항과 함께 공개 버전을 공유하여 다른 실무자가 이를 비판할 수 있도록 합니다.
- 또한 멀티 클라우드 또는 멀티 플랫폼 솔루션이 포함된 하이브리드 ML 시스템과 임베디드 시스템 MLOps 아키텍처에 대해서도 살펴볼 수 있습니다. 한 플랫폼에서 모델을 학습하고 다른 플랫폼(온프레미스, 다른 클라우드 벤더 또는 마이크로컨트롤러/엣지 장치)에서 모델을 서빙해야 하는 경우입니다.
결론
이 기사에서 다음을 배웠습니다:
- 학습 및 서빙 모두에 대한 공통 MLOps 아키텍처 패턴,
- 프로젝트에 가장 적합한 MLOps 아키텍처를 선택하는 방법,
- 프로젝트에 대한 최적의 MLOps 아키텍처를 선택하기 위한 프레임워크,
- 그리고 가장 중요한 것은:

읽어주셔서 감사합니다!
프로젝트에 가장 적합한 MLOps 아키텍처를 선택하기 위한 리소스
- 데이터 과학에 대한 비즈니스 요구 사항 분석에 대해 자세히 알아보려면 Pluralsight에서 이 과정을 확인하십시오.
- 아키텍처 템플릿은 다음에서 확인하십시오:
- MLOps 구현을 위한 강력한 도구 선택에 대해 생각하고 계십니까? Neptune.ai의 블로그에서 이 카테고리의 기사를 확인하세요.
-
실제 구현을 보고 싶으신가요? 다음에서 확인하세요:
- LinkedIn 학습에서 Kumaran Ponnambalam의 “빅 데이터 응용 프로그램 설계: 실시간 응용 프로그램 엔지니어링” 및 “빅 데이터 응용 프로그램 설계: 배치 모드 응용 프로그램 엔지니어링“에 대한 과정을 들을 수 있습니다.
- 다시 말하지만, ML 시스템을 더 잘 설계할 수 있는 또 다른 방법은 다른 사람들이 무엇을 하는지 보는 것입니다. Quora, Uber, Netflix, DoorDash, Spotify 또는 잘 알려지지 않은 다른 회사들이 어떻게 그들만의 시스템을 설계하고 있는지에 대한 웹 세미나 및 블로그 게시물이 몇 개 있습니다. 다음에서 확인하세요:
- Youtube의 MLconf 좋은 세션 영상
- Databricks Youtube 영상
- 최근 8개 기업이 어떻게 MLOps를 구현하고 있는지에 대한 기사를 작성했는데, 여기에서 확인하실 수 있습니다.
- 유용하다고 생각되는 ML 플랫폼을 처음부터 구축하는 방법에 대한 최근 릴리스입니다.
- 모든 타사 도구에서 자신과 팀을 추상화하고 각 구성 요소에 대해 별도의 도구를 사용하려는 경우, 몇 가지 우수한 MLOps 플랫폼을 사용하는 것을 고려하십시오: 머신러닝 라이프사이클을 관리하는 최적의 MLOps 플랫폼
- 주어진 과제에 대한 저의 해결책.
참고문헌
- (2688) Michael Perlin – YouTube
- Google Cloud’s training on Production Machine Learning Systems
- Machine Learning Lens – AWS Well-Architected Framework – Machine Learning Lens (amazon.com)
- AWS re: Invent 2020: Architectural best practices for machine learning applications – YouTube
- What is the difference between requirements and specifications? – Software Engineering Stack Exchange
- (1441) Architectural and Organizational Patterns in Machine Learning with Nishan Subedi – #462 – YouTube
- Spring 2021 Schedule – Full Stack Deep Learning