![]()
YOLO(You Only Look Once)는 빠른 속도와 높은 정확도를 가진 가장 널리 사용되는 딥러닝 기반 객체 감지 알고리즘 중 하나 입니다. 이 기사에서는 PyTorch 기반의 최신 YOLO 프레임웍인 ultralytics/yolov5에서 커스텀 데이터세트로 YOLOv5 모델을 학습하는 방법을 살펴보겠습니다.
YOLOv5 설치
YOLOv5 저장소를 클론 하고, 실행에 필요한 파이썬 패키지를 설치합니다.
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install -qr requirements.txt
이후 예제 코드들은 모두 yolov5 폴더를 기준으로 작성하였습니다.
docker를 사용하시는 분은 DockerHub의 ultralytics/yolov5 이미지를 사용하셔도 됩니다. 이미지 크기는 약 8GB 가량 됩니다.
docker pull ultralytics/yolov5:latest
추론 테스트
먼저 COCO 데이터셋으로 사전 학습된 모델 파일을 사용하여 샘플 이미지에서 객체 감지 결과를 보여주는 detect.py 스크립트를 실행해 봅시다.
추론에 사용된 예제 이미지는 자랑스러운 2021-22 프리미어리그 득점왕 손흥민 사진 입니다.
{kind=link}
python detect.py --source https://pds.joongang.co.kr/news/component/htmlphoto_mmdata/202101/12/680e8885-1556-4710-aa94-ba80f5ab4f49.jpg
open runs/detect/exp/680e8885-1556-4710-aa94-ba80f5ab4f49.jpg # MacOS
# eog runs/detect/exp/680e8885-1556-4710-aa94-ba80f5ab4f49.jpg # Ubuntu

YOLOv5에는 간단하게 YOLOv5 모델 추론을 테스트 할 수 있는 detect.py 파이썬 스크립트 파일이 포함되어 있습니다. 이 스크립트를 실행하여 모델 추론시 필요한 모델 파일은 최신 YOLOv5 릴리즈에서 자동으로 다운로드 됩니다. 추론 후 결과는 runs/detect/exp[실험 번호] 폴더에 기록됩니다. 사용법은 다음과 같습니다:
python detect.py --source 0 # webcam
img.jpg # image
vid.mp4 # video
path/ # directory
path/*.jpg # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
또는 다음과 같이 PyTorch Hub에서 YOLOv5 모델을 로드하여 사용 할 수도 있습니다.
import torch
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5n - yolov5x6, custom
# Images
img = 'https://pds.joongang.co.kr/news/component/htmlphoto_mmdata/202101/12/680e8885-1556-4710-aa94-ba80f5ab4f49.jpg' # or file, Path, PIL, OpenCV, numpy, list
# Inference
results = model(img)
# Results
results.print() # or .show(), .save(), .crop(), .pandas(), etc.
데이터 수집

YOLOv5 객체 감지 모델 학습에 사용하는 데이터셋은 다양한 방식으로 마련할 수 있습니다. 제품에서 사용할 이미지와 유사한 공개 데이터셋을 사용하거나 비공개 데이터셋을 구매해서 사용 할 수도 있을것 입니다. (공개 데이터셋 사용시에는 라이센스 위반 여부를 반드시 확인후 사용하시기 바랍니다.) 아니면, 제품에서 사용할 데이터를 직접 수집하여 학습 할 수도 있을 것 입니다. 여기서는 커스텀 데이터셋으로 YOLOv5 모델 학습하는 내용이므로 직접 수집한 데이터라고 가정 하겠습니다.
데이터 수집은 실제 제품에서 사용하는 환경과 가능한 최대한 동일하게 설정하여 수집하시는 것을 추천합니다. 당연하게도 모델 학습에 사용한 데이터와 실제 제품에서 추론하는 데이터가 유사 할수록 모델의 성능이 올라갑니다. 데이터 수집과 관련된 정말 다양한 요소들이 있지만 몇가지 예를 들면 다음과 같은 것들이 있습니다:
- 카메라 탑재 위치
- 카메라 설정
- 장소 및 시간
- 이미지 해상도
YOLOv5 모델 학습에는 이미지 데이터를 사용하지만, 데이터 수집 단계에는 프로젝트 특성에 따라 비디오 타입으로 데이터 수집을 하기도 합니다. 비디오 타입으로 데이터를 수집하는 경우에는 추후 데이터 가공 단계에서 비디오 파일에서 모델 학습에 필요한 이미지 파일로 샘플링하는 별도의 ETL이나 데이터 파이프라인이 필요합니다.
수집한 영상이나 이미지 파일(.mp4 또는 .jpg)을 데이터 레이크에 업로드하면 데이터 수집 과정이 완료됩니다. 데이터 레이크는 AWS S3/GCP GS/Azure Blob과 같은 오브젝트 스토리지, HDFS와 같은 분산 파일 시스템, 대용량 NAS(Network Attached Storage)등이 될 수 있습니다. 영상이나 이미지와 같은 멀티미디어 데이터 특성상 매우 큰 스토리지 저장 공간이 필요하므로 세심한 데이터 인프라 아키텍처링이 필요합니다. 이에 대해서는 추후 MLOps 인프라에 관한 기사에서 좀 더 자세히 다루어 보도록 하겠습니다.
데이터 가공
수집된 이미지 데이터에서 학습 데이터셋을 생성하기 위해서는 데이터 라벨링 작업이 필요합니다. 일반적으로 수집한 데이터를 모두 라벨링 하지는 않고, 라벨링이 필요한 이미지만 먼저 추려냅니다. 그리고 이미지 파일에 객체 테두리를 표시하는 등의 라벨링 작업을 하여 모델 학습에 사용할 어노테이션 데이터를 생성합니다.
- 수집한 데이터(Raw Data, .mp4와 같은 비디오 파일)
- (샘플링) -> 라벨안된 데이터(Unlabeled Data, .jpg와 같은 이미지 파일)
- (라벨링) -> 라벨된 데이터(Labeled Data, 이미지 파일 + 어노테이션 파일)
데이터 라벨링

DB에 추론할 대상이 되는 값이 들어 있는 정형 데이터(Structured Data 또는 Tabular Data)와 달리, 딥러닝 모델에서 사용하는 이미지나 사운드와 같은 비정형 데이터(Unstructured Data)는 사람이 직접 라벨링을 하여 어노테이션 데이터를 생성합니다. (라벨링이 필요한 데이터가 많아지면 딥러닝 워크플로우 중에서 가장 많은 리소스가 드는 단계가 됩니다.)
객체 감지 모델용 데이터 라벨링 툴은 정말 무수히 많습니다. 라벨링이 필요한 이미지에 객체의 테두리를 표시하고, 감지된 객체 종류를 기록하는 방식으로 사람이 직접 학습 데이터를 생성 합니다. 공개된 데이터 라벨링 툴 목록은 다음 링크를 참조하시기 바랍니다:
위 링크에 나열된 툴에서 라벨링이 필요한 이미지 파일 수에 따라 제가 개인적으로 추천하는 툴들은 다음과 같습니다:
- 1000장 이내: LabelImg
- 1000장 ~ 50000장: Label Studio, CVAT
- 50000장 초과: 라벨링 전문 업체에 의뢰
3대 클라우드 서비스(AWS, GCP, Azure)에서 제공하는 All-in-One ML 서비스 (SageMaker, Vertex AI, AzureML)에서도 모두 데이터 라벨링 기능을 제공하니 가격이나 편의성등을 고려하여 검토해 보시길 바랍니다.
YOLOv5 어노테이션 포맷으로 변환
데이터 라벨링이 완료되면 라벨링 툴에서 생성한 어노테이션 데이터를 YOLOv5 어노테이션 포맷으로 변환해야 합니다. YOLO 모델 어노테이션 파일은 이미지 파일과 동일한 파일명을 사용하는 텍스트 파일로 되어 있습니다. (<이미지 파일명>.txt) YOLO 어노테이션 데이터 포맷은 다음과 같습니다:
- 한 라인에 하나의 객체에 대한 어노테이션을 기록함
- 한 라인의 어노테이션 포맷은
<class><x_center><y_center><width><height>으로 구성됨 - 박스의 좌표는 0~1 사이 부동소수점 값으로 정규화
- 클래스 넘버는 0부터 시작
요즘은 라벨링 툴에서 YOLO 어노테이션 포맷을 지원하여 어노테이션 포맷 변환이 필요 없는 경우도 많습니다.
어노테이션 포맷 변환 및 모델 학습 실습을 위해 Udacity 자율 주행 자동차 데이터셋으로 YOLOv5 모델 학습을 해보겠습니다. 이 데이터셋을 다운로드하면 이미지 파일과 어노테이션 파일 (.csv 포맷)이 압축된 archive.zip 파일이 다운로드 됩니다. 이 데이터셋의 어노테이션 파일은 다음과 같이 테이블 형태의 .csv 파일로 되어 있습니다.
-
클래스 맵
Class ID Class Name 1 car 2 truck 3 pedestrian 4 bicyclist 5 light -
labels_train.csv파일 내용 일부frame xmin xmax ymin ymax class_id 1478019952686311006.jpg 237 251 143 155 1 1478019952686311006.jpg 437 454 120 186 3 1478019953180167674.jpg 218 231 146 158 1 1478019953689774621.jpg 171 182 141 154 2 1478019953689774621.jpg 179 191 144 155 1
이 CSV 어노테이션 파일에서 YOLO 포맷으로 변환하기 위해서는 다음과 같은 작업을 해야 합니다:
- 각 행은 하나의 객체에 대한 정보를 나타내므로
frame필드로 그룹화 및<이미지 파일명>.txtYOLO 어노테이션 파일 생성 xmin,xmax,ymin,ymax->x_center,y_center,width,height- 박스의 각 모서리 좌표에서 박스 중앙 좌표와
width,height값으로 변환 - 0 ~ 1 사이의 부동 소수점 값으로 정규화
- 박스의 각 모서리 좌표에서 박스 중앙 좌표와
class_id필드의 클래스 ID 값은 1부터 시작하므로 1씩 감소 (YOLO는 0부터 시작)
이를 파이썬 코드로 표현하면 다음과 같습니다:
from pathlib import Path
import pandas as pd
IMG_WIDTH = 480
IMG_HEIGHT = 300
# 'dataset_path'는 다운로드 한 'archive.zip' 압축 푼 경로
#dataset_path = "../datasets/sample_dataset"
image_file_path = dataset_path + "/images"
df = pd.read_csv(dataset_path + "/labels_trainval.csv")
def box2d_to_yolo(box2d):
# 0~1 사이 값으로 정규화
x1 = box2d["xmin"] / IMG_WIDTH
x2 = box2d["xmax"] / IMG_WIDTH
y1 = box2d["ymin"] / IMG_HEIGHT
y2 = box2d["ymax"] / IMG_HEIGHT
# 모서리 좌표에서 센터 좌표로 변환
cx = (x1 + x2) / 2
cy = (y1 + y2) / 2
# width, height 구함
width = abs(x2 - x1)
height = abs(y2 - y1)
return cx, cy, width, height
assert Path(image_file_path).is_dir(), "Output directory doesn't exist"
labels_dir = Path(dataset_path + "/labels").absolute()
Path(labels_dir).mkdir(exist_ok=True)
# 이미지 파일('frame' 필드)로 그룹화하여 처리한다.
for frame, v in df.groupby(['frame']):
img_name = Path(frame)
assert img_name.suffix == ".jpg"
frame_name = str(img_name.stem)
annotation_file = labels_dir / (frame_name + ".txt")
with open(annotation_file, "w") as anno_fp: # 어노테이션 파일 생성
for _, row in v.iterrows():
cx, cy, width, height = box2d_to_yolo(row)
class_id = row['class_id'] - 1
anno_fp.write(f"{class_id} {cx} {cy} {width} {height}\n")
assert len(list(labels_dir.glob('*.txt'))) == len(df.groupby(['frame']))
학습 데이터와 검증 데이터셋 목록 파일을 작성합니다. 데이터셋 별 경로를 지정할 수도 있지만, 현재 사용하는 데이터셋은 학습/검증/테스트에 사용되는 이미지 파일이 모두 동일한 경로에 있으므로 데이터셋 파일 목록 파일 (train.txt, val.txt, test.txt)을 생성하여 사용하는 편이 좋습니다. 데이터셋 경로를 지정하면 YOLOv5는 이미지 파일 경로에서 images를 labels로 대체하여 해당되는 어노테이션 파일을 찾습니다.
train_df = pd.read_csv(dataset_path + "/labels_train.csv")
val_df = pd.read_csv(dataset_path + "/labels_val.csv")
with open(dataset_path + "/train.txt", "w") as fp:
for file_name in pd.unique(train_df['frame']):
fp.write(f"{image_file_path}/{file_name}\n")
with open(dataset_path + "/val.txt", "w") as fp:
for file_name in pd.unique(val_df['frame']):
fp.write(f"{image_file_path}/{file_name}\n")
YOLOv5 모델 학습
데이터셋 설정 파일
YOLOv5 모델 학습에 기본적으로 필요한 것들은 다음과 같습니다:
- 이미지 파일들 (
.jpg또는.png) - YOLO 어노테이션 파일들 (
.txt) - 데이터셋 설정 파일 (
<데이터셋 이름>.yaml)
이 외에도 하이퍼파라메터 설정 (--hyp 옵션) 및 모델 네트워크 설정 (--cfg 옵션)등 모델 학습과 관련하여 많은 설정을 할 수 있지만 나머지 설정은 기본 설정을 그대로 사용하겠습니다.
데이터셋 설정 파일에는 학습/검증/테스트 데이터셋 경로 및 클래스 개수와 이름을 설정하도록 되어 있습니다. Udacity 자율 주행 자동차 데이터셋 학습을 위해서는 아래와 같이 설정하여 사용합니다:
custom_dataset.yaml
path: ../datasets/sample_dataset # dataset_path
train: train.txt # train images
val: val.txt # val images
# Classes
nc: 5 # number of classes
names: [ 'car', 'truck', 'pedestrian', 'bicyclist', 'light' ] # class names
모델 선택
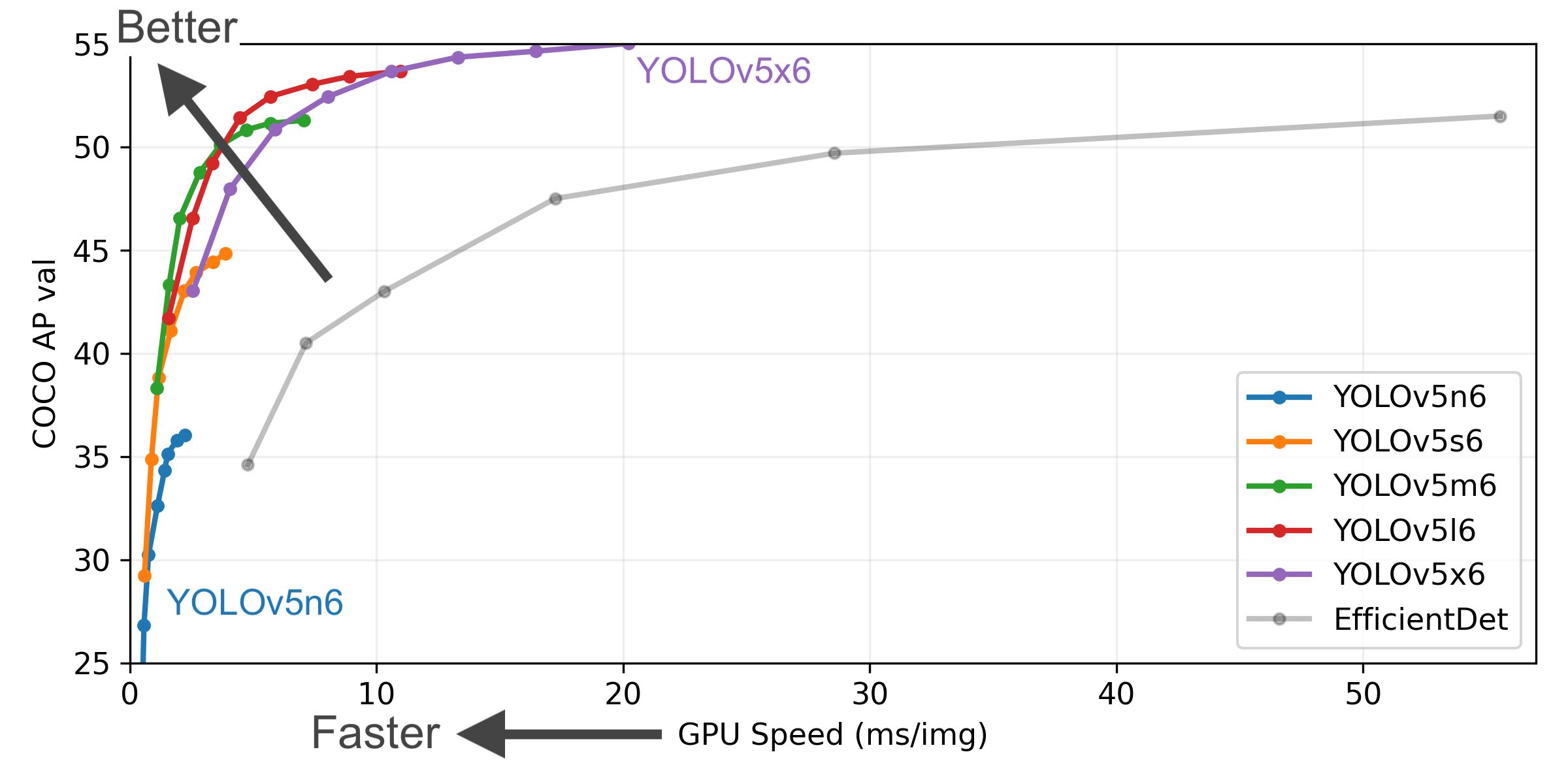
이 기사 초반부에 YOLOv5 모델 네트워크 크기에 따른 추론 속도 및 정확도에 대한 그래프를 첨부 하였습니다. 추론 속도와 정확도는 트레이드오프이므로 ML 어플리케이션에 따라 적절한 모델을 선택해서 사용하시기 바랍니다.

학습 스크립트 실행
YOLOv5에는 train.py라는 모델 학습에 사용하는 파이썬 스크립트가 포함되어 있습니다. 지금까지 준비한 커스텀 데이터셋 (.jpg, .txt)과 데이터셋 설정 파일 (custom_dataset.yaml)을 사용하여 train.py 스크립트로 모델 학습을 수행합니다:
python train.py --batch-size 16 --epochs 10 --data custom_dataset.yaml --weights yolov5n.pt
--batch-size옵션은 모델 학습시 한번에 처리할 배치 크기를 의미합니다. 이 옵션 값이 클수록 모델 학습 시간이 단축 됩니다. GPU 메모리 크기에 맞춰 설정합니다.--epochs옵션은 학습 데이터셋이 모델을 통과한 횟수를 의미합니다. 이 값이 클수록 학습 시간이 길어지며 모델은 학습 데이터셋에 피팅 됩니다.--weights옵션은 학습에 사용할 PyTorch 모델 체크포인트 파일을 의미 합니다. (yolov5n.pt/yolov5s.pt/yolov5m.pt/yolov5l.pt/yolov5x.pt)--data옵션은 앞서 생성한 데이터셋 설정 파일 지정 옵션 입니다.
YOLOv5 모델 학습 결과
모델 학습과 관련된 모든 파일은 runs/train/exp[실험번호] 경로에 저장 됩니다.
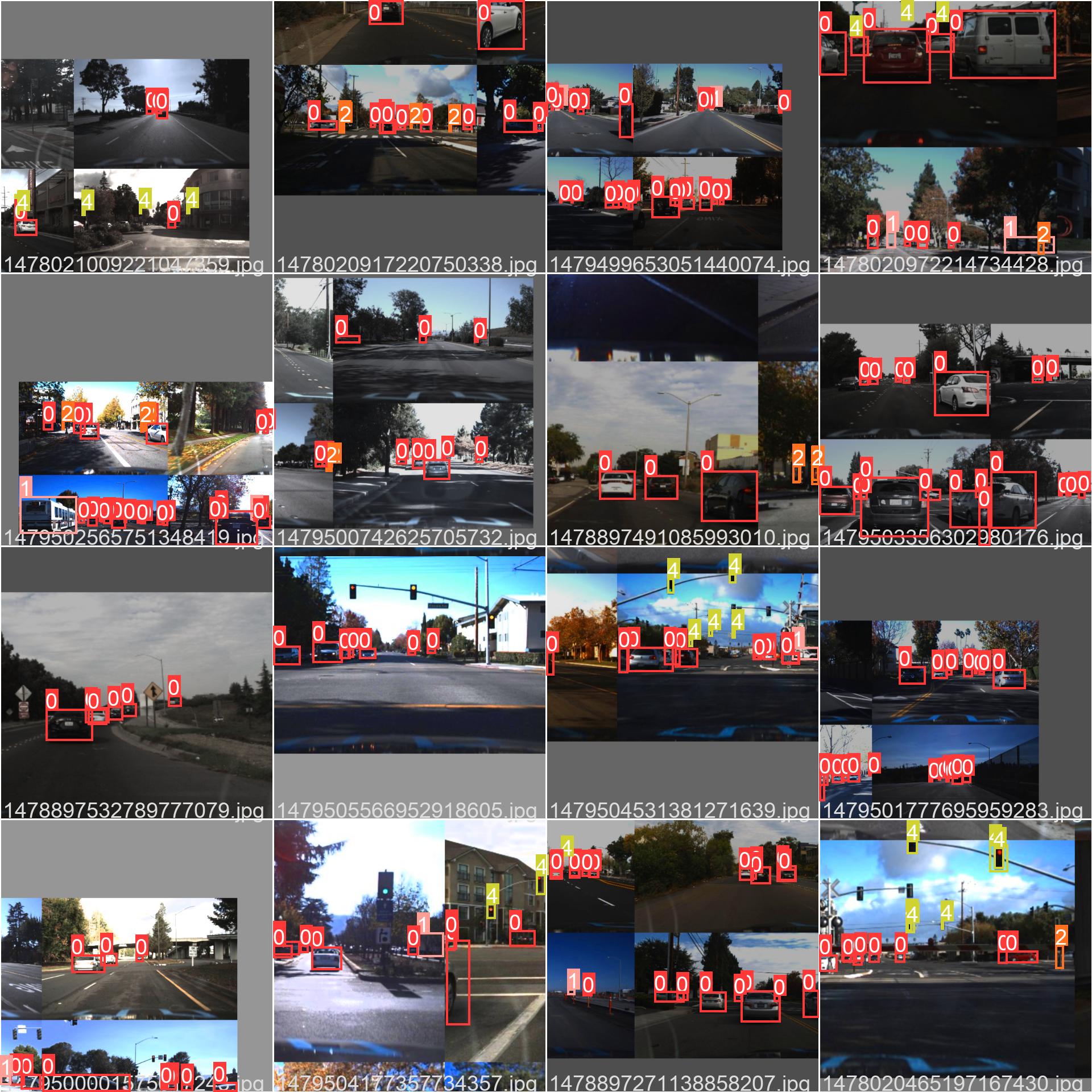
- 클래스 분포와 학습 데이터 배치 시각화

학습 결과는 runs/train/exp[실험번호]/results.csv 파일에 저장되어 있습니다.
from utils.plots import plot_results
plot_results('./runs/train/exp/results.csv') # plot 'results.csv' as 'results.png'

학습된 모델 추론 테스트
학습된 모델 체크포인트 파일은 runs/train/exp[실험번호]/weights 폴더에 저장됩니다. 다음과 같이 detect.py 스크립트 실행시 모델 체크포인트 파일(--weights)을 학습된 모델 체크포인트 파일로 설정하여 추론 테스트를 할 수 있습니다:
python detect.py --source ../datasets/sample_dataset/images/1479503426306710339.jpg --weights runs/train/exp/weights/best.pt --conf 0.25
open runs/detect/exp2/1479503426306710339.jpg
